11.1. 异常检测问题
本文最后更新于 2025年6月4日 晚上
异常检测问题
异常检测(Anomaly detection)算法是另一种常在非监督学习中使用的算法。这种算法虽然常常用于非监督学习,但与监督学习有许多相似之处。
对于一个非监督学习的数据集,假定数据集里的数据都是正常或异常的,此时加入一个新的数据,判断其在空间内的分布是否异常(符合现有数据集的分布规律)的问题称为异常检测问题。
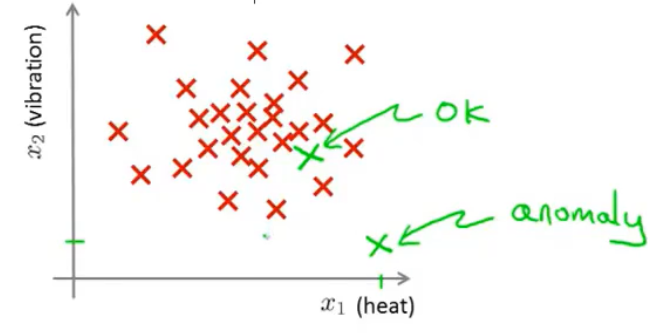
解决这类问题,基本思路是对现有数据集的分布概率进行建模:设数据集\(X\)的分布概率模型为\(p(x)\),然后检测新数据\(x_{test}\)的分布概率为\(p(x_{test})\),通过设定一个阈值\(ɛ\)来检测\(x_{test}\)是否异常:如果\(p(x_{test})<ɛ\),则判定\(x_{test}\)的数据出现了异常。
概率分布模型\(p(x)\)在数据密集的中心区域位置的值很高,越疏离中心,\(p(x)\)的值越低。
应用案例
- 用户欺诈行为检测
- 产品质量检测
- 生产监控
- …
11.1. 异常检测问题
https://l61012345.top/2021/08/21/机器学习——吴恩达/11. 异常检测算法/11.1. 异常检测/