13.1. 大规模学习的计算问题·预学习
本文最后更新于 2025年6月4日 晚上
大规模学习的计算问题·预学习
在机器学习中,起决定因素的往往不是最好的算法,而是谁有大量的数据。机器学习发展的近10年到近5年的时间中,社会生活所产生的数据量不断增大,机器学习更倾向于学习更大规模的数据集。
接下来一章将讨论如何处理大数据集。
计算问题
大数据集学习面临的首要问题是计算问题。
假设训练集大小为\(m=100,000,000\)(这个数据是非常现实的,以美国人口为例,美国人口大约3亿,如果查询这些人的某些数据,数据量能够轻松地达到上亿规模),此时直接应用传统算法在计算量上会有很大的难度。以梯度下降算法为例:此时如果想要应用批量梯度下降来最小化代价函数,批量梯度下降的更新公式为:
\[θ_j:=θ_j-α\frac{1}{m}∑_{i=1}^m(h_θ(x^{(i)})-y^{(i)})x_j^{(i)}\] 按照\(m=100,000,000\)来算,梯度下降算法需要对一亿个项求和,这显然是非常不现实的工作。
有两种适用于大规模机器学习、处理大规模数据的算法为:
- 随机梯度下降 (Stochastic gradient desent)
- 减少映射(Map reduce)
预学习
不过在正式开始对大数据的学习之前,有必要弄清楚一个问题:究竟有没有必要使用这么多数据来进行训练?
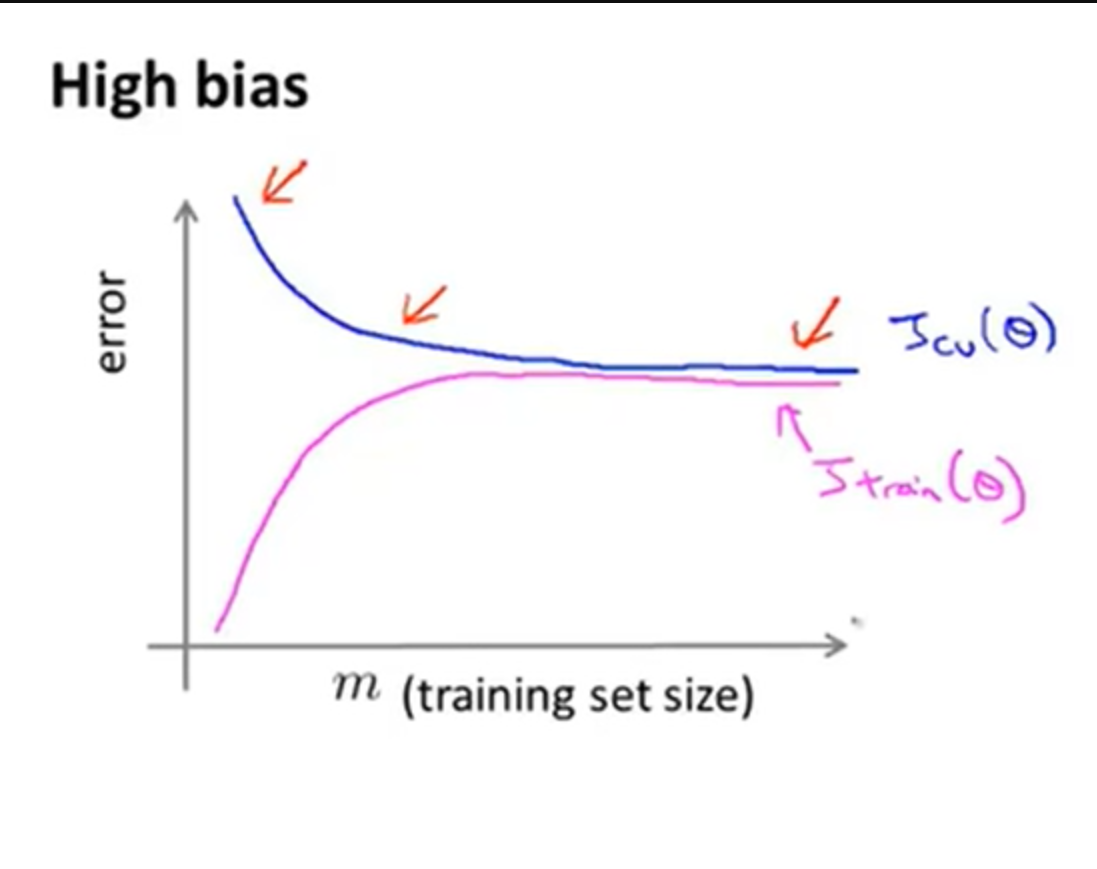
一种有效的方法是随机选择这一亿个数据中的一小部分(比如1000个数据)进行预学习,绘制6.3. 学习曲线。 观察此时的学习曲线是否表征出现了高方差特性(如下图所示),由于高方差问题是可以通过增大数据量来改善的,在这种情况下才更应当增加数据集的量来学习。
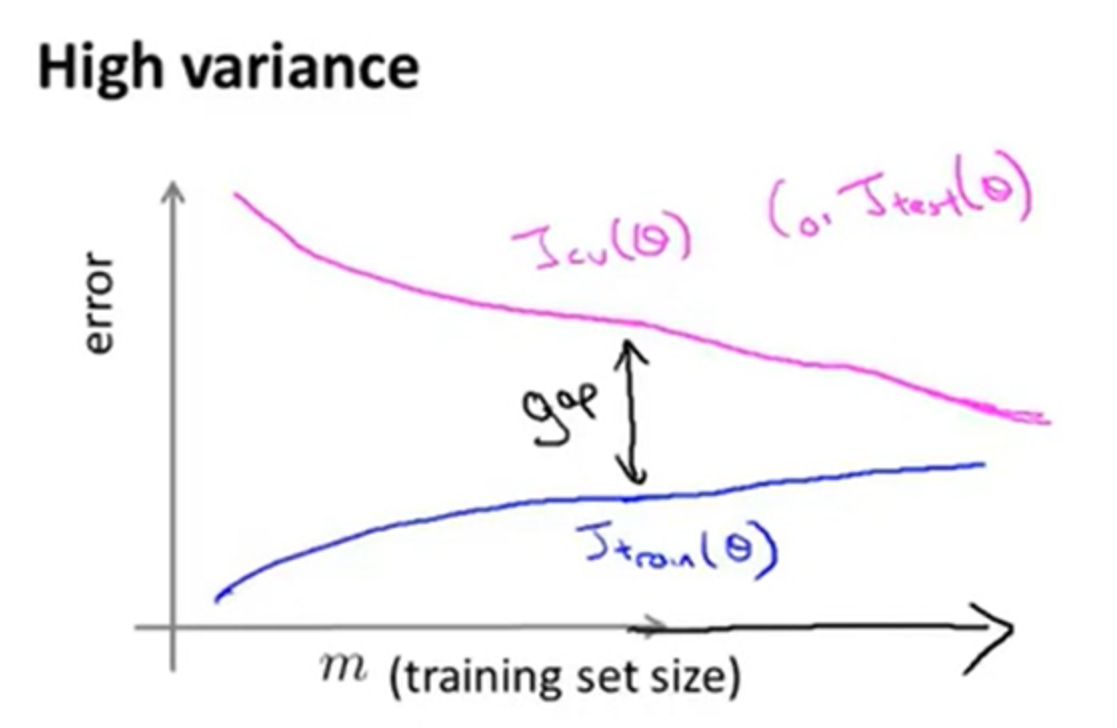
倘若学习曲线未出现高方差特性,或者是出现了高偏差特性(如下图所示),此时增大数据量对机器学习的效果不会有太大改善。