14.2. 滑动窗口分类器
本文最后更新于 2025年6月4日 晚上
滑动窗口分类器
上一节中照片OCR系统的流水线:

本节课将着重于“Text detection”文字检测的部分,这一部分的功能由一种称为滑动窗口分类器(Sliding window classifier)的算法承担。
滑动窗口分类器能够全局扫描整幅图像并检测图像上的有文字的部分。
案例:行人检测
滑动窗口的最经典应用是行人检测,相比于文字检测要简单的地方在于:行人检测所检测的目标拥有相似的长宽比。
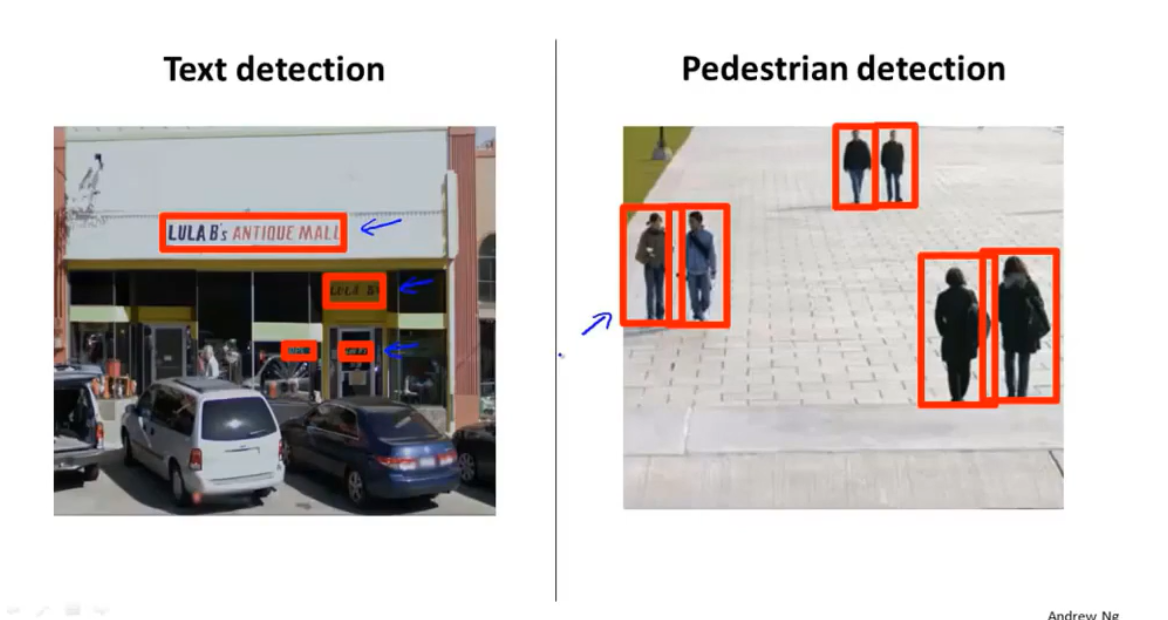
制作分类器
为了识别行人,需要制作一个监督学习分类器,分类器需要识别图像是否是行人,具体的做法如下:
收集一个行人的数据集,这个数据集由正样本和负样本组成。其中正样本是行人的图片,要求行人需要占到这个图像的相当大的部分。负样本则是一些没有行人的街景图像,大小和行人相同,这些图像要求种类尽量多一些(比如房屋、树木等等)。

全幅扫描
现在,给出一个有若干行人的全幅图像,算法需要在图像中选取一个矩阵块(即窗口),将这个矩阵块中的图像部分传入上一布设置好的分类器当中,并对这部分图像进行识别,判断这部分图像中是否有行人。

接着,这个窗口会稍微移动一些,并将窗口内的新内容传递给分类器,再次识别。
窗口移动的大小称为步长(Stride/Step size),如果步长设置的很小,那么总计需要识别的图块数量就会增多,增加计算量。如果步长设置的很大,那么窗口可能不会覆盖到图像的某些区域。
常见的设置是将步长设置在4-8像素。
滑动窗口直到图像所有的位置都被这个窗口扫过一遍。
接着,设置一个面积更大的图块,再次对图像进行扫描。
设置更大图块的目的是为了识别更多尺寸的目标。
实例:文字检测
在文字检测中,同样地思路训练一个分类器。
放大算子
同样地运用滑动窗口识别字符,但是在识别完成之后,需要应用放大算子对监测到文字的区域进行拓展。即将识别到的文字区域稍微向四周扩展一些,以便检测这些文字区域的周围是否还有未识别到的,或者是不完整的文字。

如上图所示,左边的灰度图是一种可视化识别结果的方式:白色表示该区域滑动窗口识别到了文字,而灰色区域的灰度表示可能为文字区域的概率,黑色区域表示这些区域内没有文字。
右边的灰度图表示将左图应用放大算子后的结果。
检测长宽比
接下来对识别到的文字区域进行排除,舍弃一些长宽比较为反常的、分类器认为是文字的区域。(比如:英语中很少有竖着写的情况,因此宽度过分大于长度的区域应当被舍弃)
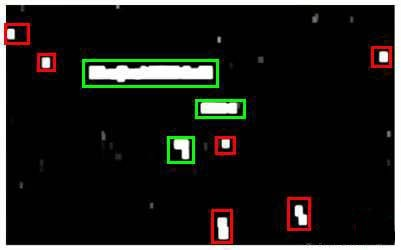
上图的绿色区域是经过检测长宽比后被认为是文字的区域,而红色的区域是检测长宽比后被舍弃的区域。