14.4. 人工数据合成
本文最后更新于 2025年6月4日 晚上
人工数据合成
通过之前的学习,可以得出机器学习的实质是使用一个低偏差的算法学习一个相对庞大甚至是非常庞大的数据集,如何获得大量的数据集呢。实际上,有时寻找一些特定的数据集是非常困难的,通常有如下的几种思路可以获得大量数据:
- 人工数据合成
- 手动标记标签
- 雇佣众包来标记数据
本节主要介绍一种称为人工数据合成的方法。人工数据合成可以通过生成数据集或者是对现有的数据集进行扩增以增加数据量。
下面将以光学字符识别为例,介绍人工数据合成所采用的两种策略。
生成数据集
要获得识别光学字符识别所需要的大量数据集,一个办法是通过计算机字体库自动生成一些单独的字符图像,与任意的背景进行组合,从而人为地创造数据集。

如上图所示的合成数据(图左),可以发现通过这种方式创造的数据集事实上和真实数据集(图右)之间的差别不大。
数据集扩增
数据集扩增是建立在原有的少量数据集之上。对于光学字符识别所需要的字符图像,一种可行的办法是对图像进行各种拉伸以创造新的图像,如下图所示:
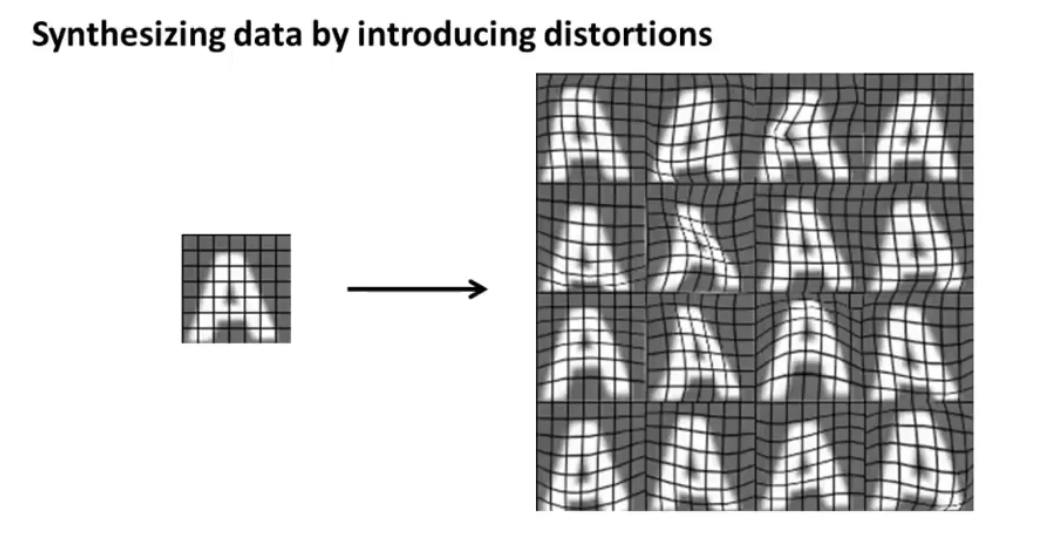
扩增的核心思想是对现有的数据人为地加入一些噪音或者变换,以制造更多的可能数据。
需要注意:这些噪声和变换的目的是为了增加数据集中的丰富性,从而使得算法能够应对更多的场景。因此这些噪声和变换需要是在现实中可能出现的、有意义的,以模拟识别目标的多样性和真实性。
注意事项
- 在进行人工数据合成之前,仍然要保证算法处于低偏差状态。
- 在进行人工合成之前,需要评估这样做的工作量。评估花这么多的工作量是否值得。如果以很小的代价就能够获得10倍乃至更多的数据,那么这样的工作是值得的。
14.4. 人工数据合成
https://l61012345.top/2021/08/28/机器学习——吴恩达/14. 机器学习实例:OCR/14.4. 获得大量数据/