智能系统部分-知识点总结
本文最后更新于 2025年6月4日 晚上
智能系统部分-知识点总结
机器学习包括了四种类型:
| 监督学习 (supervised learning) |
机器学习数据及其对应的标签/输出,从而生成模型。 |
| 无监督学习 (unsupervised learning) |
机器根据输入的数据自动挖掘数据特征,以此建模,不需要输入数据对应的标签。 |
| 半监督学习 (semi-supervised learning) |
监督学习与无监督学习相结合的一种学习方法。半监督学习使用大量的未标记数据,以及同时使用标记数据,来进行模式识别工作。 |
| 增强学习 (reinforcement learning) |
一种反馈学习系统。由智能体(Agent)、环境(Environment)、状态(State)、动作(Action)、奖励(Reward)组成。智能体执行了某个动作后,环境将会转换到一个新的状态,对于该新的状态环境会给出奖励信号(正奖励或者负奖励)。随后,智能体根据新的状态和环境反馈的奖励,按照一定的策略执行新的动作。 |
神经网络
感知机
下图展示了神经网络中一个神经元的结构:
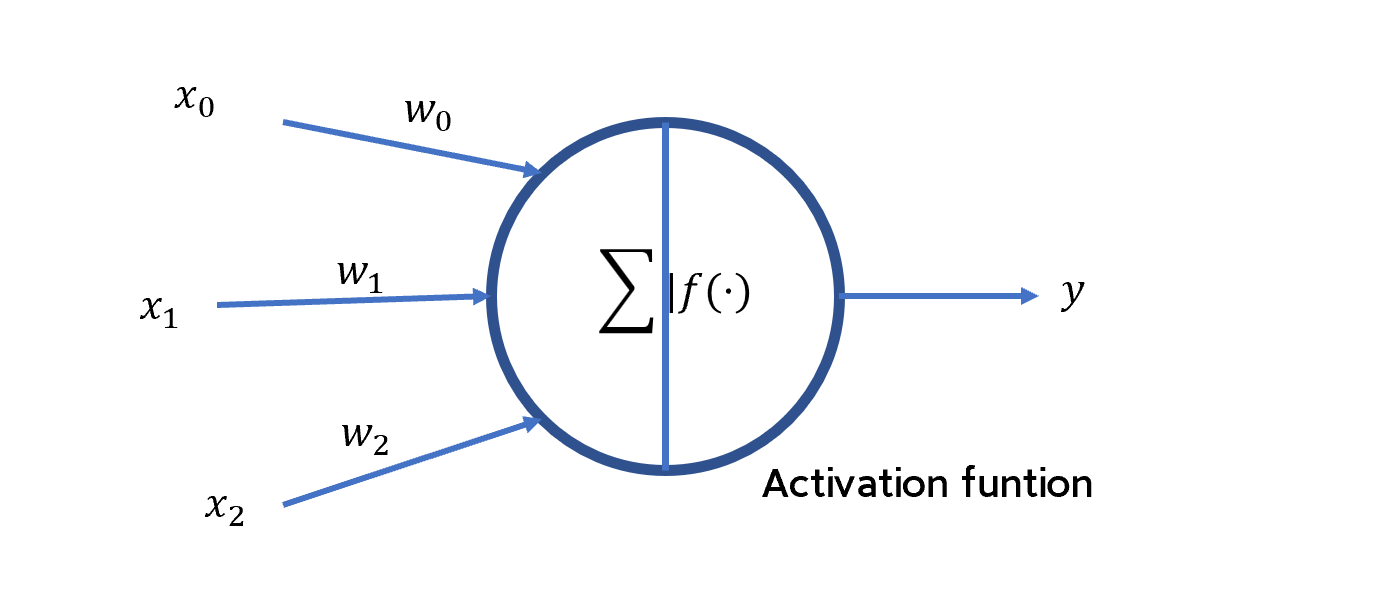
如上图所示,假设对一个神经元,其输入为来自若干其他神经元的输出\(x_i\),那么该神经元的输出\(y\)可以用数学公式表达为:
\[y=f\left[(∑_{i=0}w_ix_i)+b_i\right]\] 其中\(b_i\)表示该神经元的偏置(offset),用于线性修正;\(f[·]\)是该神经元的激活函数。每一个神经元中的激活函数承担了对数据进行简单处理的任务。激活函数可以是线性的,也可以是非线性的。
这样的由一个神经元构成的神经网络称为感知机(perceptron)。通过选择合适的激活函数和权重,这样的单层神经网络可以实现一些基本的逻辑函数功能、例如逻辑与(AND)、逻辑或(OR)、逻辑非(NOT)等。
感知机的问题是无法提取数据的非线性特征。
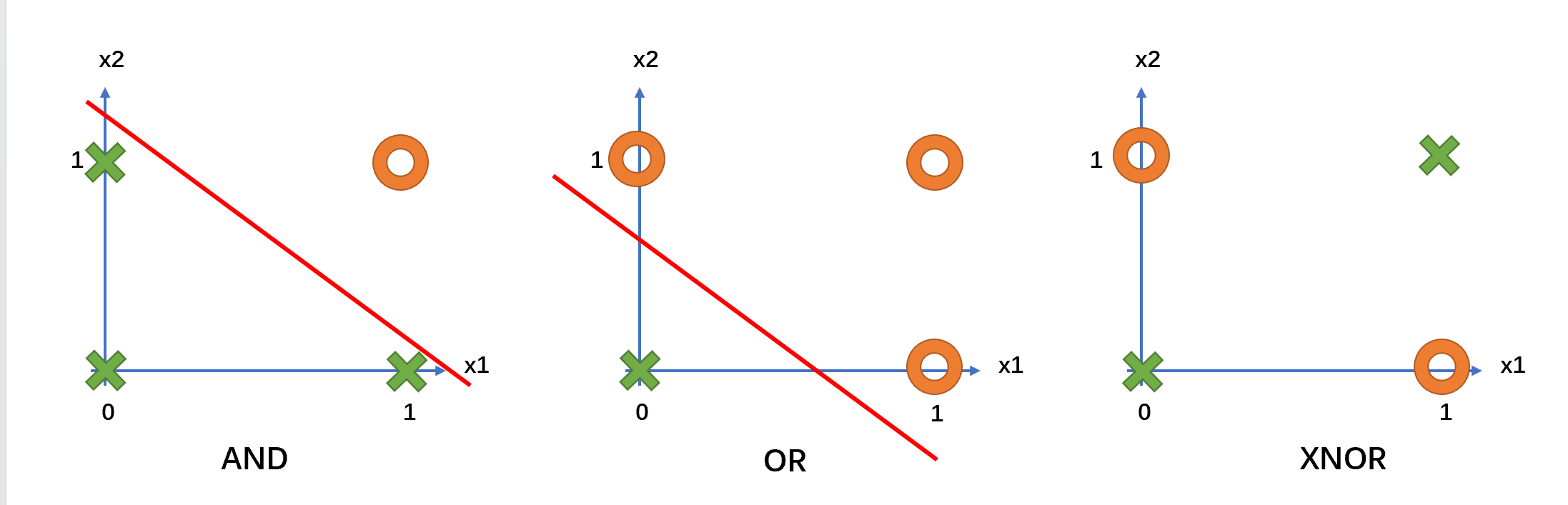
可以发现AND和OR在样本空间中的表示都可以用一条直线对其进行划分,而对XNOR无法找到一条直线将其进行区分。对于感知机而言,由于其输出表示为多个神经元的线性组合,通过Sigmoid函数,只能找到数据的线性边界。 对于这样的非线性逻辑函数,需要添加多层神经元才能完成逻辑函数的功能。
多层神经网络
整个神经网络的学习过程包括:
- 随机初始化连接权重
- 当均方差非常大,或者数代均方差变化很大时,执行如下的循环:
- 前向传播:带入每一个数据\((x_i,y_i)\)中的\(x_i\)到神经网络中,计算神经网络中每一个神经元对每一个数据的输出\(a_{jk}\)和神经网络对每一个数据的预测值\(\hat{y}\),并整理为向量。
- 计算真实值\(y\)与预测值\(\hat{y}\)之间的差距。
- 使用验证集对神经网络的准确率进行测试。
- 反向传播:计算\(δ\)并更新每一层每一条连接的权重。
- 前向传播:带入每一个数据\((x_i,y_i)\)中的\(x_i\)到神经网络中,计算神经网络中每一个神经元对每一个数据的输出\(a_{jk}\)和神经网络对每一个数据的预测值\(\hat{y}\),并整理为向量。
- 使用测试集对训练好的神经网络的准确率进行测试。
前向传播
简单来说,前向传播的过程即将数据\(x\)带入到神经网络的表示中,得到输出的过程:
\[\hat{y}=a^{(N)}=f(z^{(N)})\]
\(N\)表示神经网络最后一层的标识。
在前向传播的过程中,会得到每一个神经元的输出\(a_{jk}\)
反向传播
反向传播的过程是根据实际值和预测值之间的误差,从输出层开始,逐层调整各层神经元连接权重的过程。
在输出层第\(N\)层,根据得到的预测结果\(\hat{y}\),使用如下式子来衡量与实际结果\(y\)之间的差距:
\[δ^N_{jk}=(y_j-\hat{y}_j)\hat{y_j}(1-\hat{y_j})\] (\(\hat{y}_j\)和\(y_j\)都是向量,其维度等于数据集大小)
对于隐藏层的神经元,如下式子表示了其神经网络单元输出的修正:
\[δ^i_{jk}=a^i_j(1-a^i_j)∑_{m}δ^{i+1}_{mj}w^{i+1}_{mj}\] 简单来说即\(a^i_j(1-a^i_j)\)后一层中与该神经元相连的神经元的权重和修正的乘积。
权值的修正过程表示为:
\[Δw_{jk}=ηδ_{jk}a^i_j\] \[w_{jk}:=w_{jk}+Δw_{jk}\] 其中,\(η\)是一个可以调整的参数,称为学习率(learning rate)。通过学习率可以控制权值一次性更新的幅度,换言之,即学习的快慢。学习率越大,权重更新的幅度越大,学习速度越快。
上面所示的这个权重修正的方法称为梯度下降算法(gradient desent)。
如此,神经网络在反复的前向传播和反向传播迭代(每一次迭代称为一轮,epoch)中不断地修正各连接的权重,直到使得真实值\(y\)与预测值\(\hat{y}\)之间的差距小到可以接受或者一直不变。这种情况称算法运行达到了收敛(convergence)。 通常,真实值\(y\)与预测值\(\hat{y}\)之间的差距是通过均方差(MSE,Mean Square Error)进行衡量的:
\[MSE=\frac{1}{n}∑_{i=0}^{n-1}(\hat{y}_i-y_i)^2\]
调试
动量*
为了避免算法陷入局部最小值,目标函数中使用了动量(momentum),该动量项\(α\)是介于0和1之间的值,该值通过尝试从局部最小值跳到最小值而增加了步长。如此,修正后的权重应当为:
\[Δw_{ij}:=ηδ_ja^i_j+αΔw_{ij}\] 如果动量项较大,则学习率应该保持较小。动量值很大也意味着收敛将很快发生。但是如果将动量和学习率都保持在较高的值,那么算法可能会大步跳过最小值。
较小的动量值不能可靠地避免局部最小值,并且还可能减慢系统的训练速度。如果梯度不断改变方向,动量也有助于平滑变化。
正确的动量值可以通过命中和试验来学习,也可以通过交叉验证来学习。
过拟合
过拟合(overfitting)指神经网络的模型对数据的拟合的程度过高,过拟合意味着模型泛化能力低。模型能够很好的拟合当前的数据集,但是并不适应新的数据。
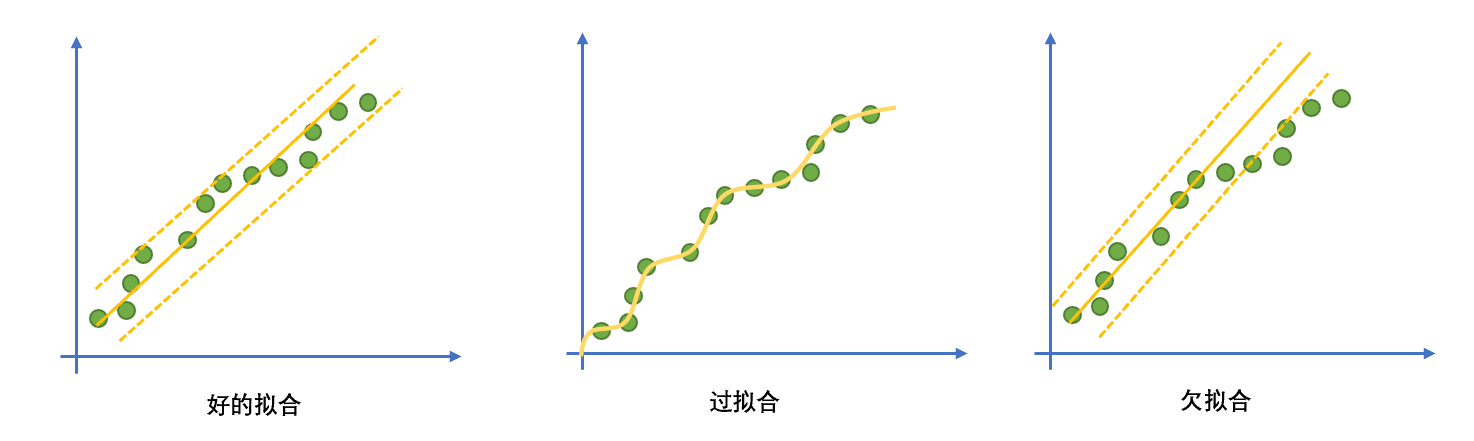
过拟合的模型波动较大、具有高方差的性质。
过拟合可以通过如下方法解决:
- 使用验证集,实时监控训练过程中准确率/方差的变化,当准确率达到要求时停止训练。
- 设置训练轮数,达到轮数后停止训练。
- 设置方差阈值,训练过程中方差达到阈值时停止训练。
超参数
像学习率和动量这样的并非通过反向传播调整、而是在训练的开始就设置好的参数称为超参数(hyper-parameter)。对超参数进行调整的目的是为了改进学习过程的准确率和收敛速度。
| 参数 | 过大结果 | 过小结果 |
|---|---|---|
| 训练轮次 | 过拟合 | 欠拟合 |
| 学习率 | 学习过程不稳定 | 收敛缓慢 |
| 动量系数 | 过拟合 | 陷入局部最小值 |
| 神经元数量 | 过拟合 | 无法充分提取特征 |
迁移学习
迁移学习(transfer learning)是一种学习方式,其使用用某个数据集训练好的权重神经网络,冻结训练好的某些层中的权重,再用这个网络训练另一组全新类型的数据集,这次训练中冻结的权重将不会发生任何改变。
迁移学习可以改进数据集数据量小导致的问题。
其他类型的神经网络
除了基于反向传播的神经网络外,神经网络还有其他的几种类型。
自组织映射
自组织映射(SOM,self-organizing map)是一种只有两层的无监督学习神经网络。通过学习输入空间中的数据,生成一个低维、离散的映射(Map),从某种程度上也可看成一种降维算法。它最重要的应用是用于聚类(clustering)。
不同于一般神经网络基于损失函数的反向传播来训练,它运用竞争学习(competitive learning)策略,依靠神经元之间互相竞争逐步优化网络。且使用近邻关系函数(neighborhood function)来维持输入空间的拓扑结构。
SOM的结构如下:
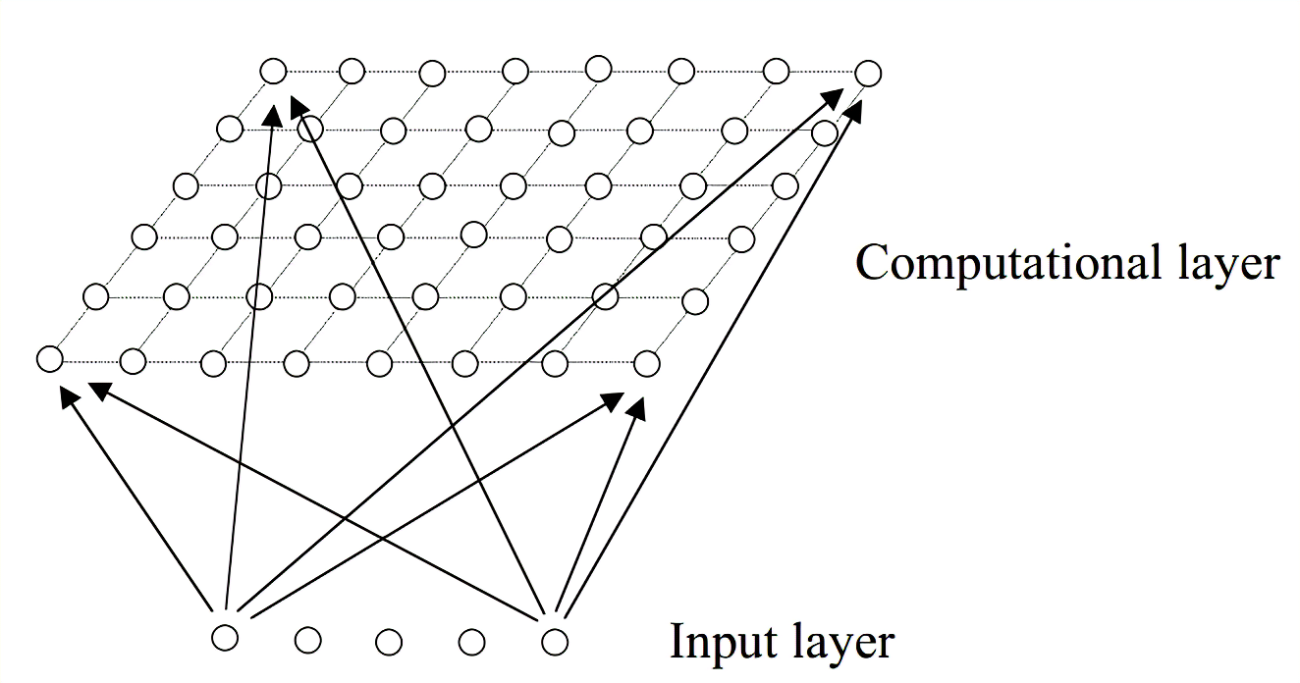
SOM只有两层,第一层为输入层,第二层为输出层,也称为竞争层(computational layer)。
输入层神经元的数量是由输入向量的维度决定的,一个神经元对应一个特征。
竞争学习策略
对于SOM而言,神经网络中的权重仍然要进行随机初始化。其后权重的更新仍然基于权重更新算法:
\[w:=w+ηδa\] 然而,由于其是一个无监督学习算法,无法对网络输入数据集的标签,因此此处的\(δ\)采用数据点\(\boldsymbol{X}\)到每一个神经元的权重之间的欧氏距离进行衡量:
\[d=||\boldsymbol{X}-\boldsymbol{W}||=\sqrt{∑(x_i-w_i)^2}\] 与基于反向传播的神经网络不同的是,此处需要计算数据点到所有神经元的欧氏距离,并且找到到该数据点欧氏距离最短的神经元\(\boldsymbol{W_{win}}\)。然后使用该输入对该神经元的权重进行更新:
\[\boldsymbol{W_{win}}:=\boldsymbol{W}+η(\boldsymbol{X}-\boldsymbol{W_{win}})\] 此外,这个神经元的权重\(\boldsymbol{W_{win}}\)还会对周围的神经元的权重造成影响,影响的大小服从近邻关系函数\(θ(N)\),其中\(N\)表示的是影响范围内某个神经元距离赢家的神经元距离,下图表示了\(N=1\)和\(N=2\)时赢家(编号为13的神经元)对周围神经元的影响;

\(θ(N)∈[0,1]\),表示该距离所对应的对其权重的影响与原来的百分比。赢家周围的神经元的权重更新表示为:
\[\boldsymbol{W_{neigh}}:=\boldsymbol{W}+η(\boldsymbol{X}-\boldsymbol{W_{neigh}})θ(N)\]
训练完成后,所有的数据点都被映射到竞争层的神经元,在竞争层观察到竞争层的神经元移动到输入层数据密集的区域,从而自发地形成数据簇,完成聚类。
循环神经网络
循环神经网络(Recurrent Neural Network, RNN)是一种专用于设计处理时序数据的神经网络,其结构上与普通的多层神经网络不同的是,它的隐含层具有自循环的结构,通过这样的自循环,当前的隐含层神经元的输出与上一个时刻神经元的输出建立联系。
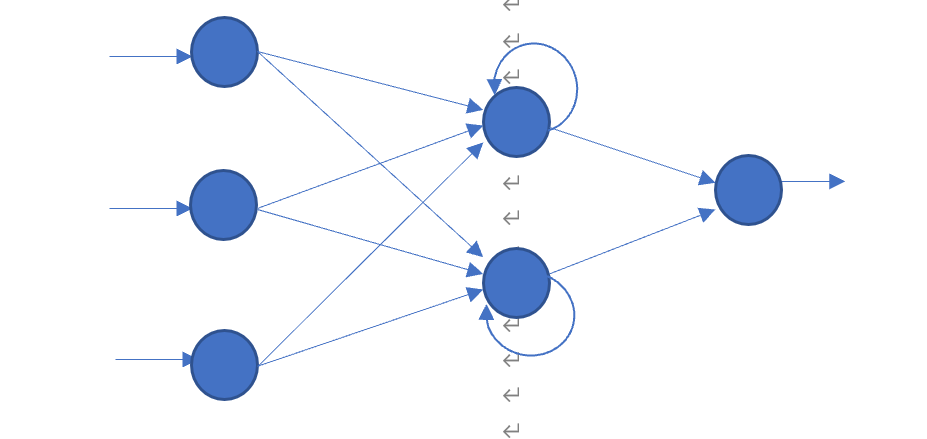
循环神经网络的前向传播过程类似于普通的神经网络,它每个神经元的输出可以表示为:
\[y(t)=f\left[(∑_{i=0}w_ix_i(t))+b_i+y(t-1)\right]\] 反向传播过程和普通的神经网络相同,但是需要更新自循环的权重。
卷积神经网络·深度学习
卷积神经网络(Convolutional Neural Network, CNN)是一种最初设计用于处理图像的神经网络。它可以看做是一组自适应图像滤波器,其每一层的神经元是用于处理图像的卷积核,卷积核内的参数通过反向传播进行修正。
卷积神经网络属于深度学习(deep learning)的范畴,相比于一般的神经网络,它们具有如下特点:
- 通过设置一系列的、更加复杂的级联网络结构可以深度挖掘数据的非线性特征。
- 深度学习网络通常具有分层级的表示和结构。
- 可以是监督学习也可以是非监督学习。
模糊系统
模糊逻辑基于模糊集论(fuzzy set theory),它试图使用近似和不确定的信息来模仿人类的直觉推理。模糊集论使用数学表达来描述这样的不确定和模糊。
基本定义
隶属度
对于传统的布尔逻辑,对某件个事件的描述分类是非黑即白的,即是二值的(crisp)。而在模糊逻辑中,对于某个事件的描述分类是基于概率分布的,称为隶属度(DoM,Degree of Membership),这是一种多值逻辑。
模糊集和隶属度函数
模糊集(fuzzy set)表示隶属于某个类别的所有个体。模糊集中所有个体各自的某一属性的所有可能取值(称为论域,univsersal of discourse)以及这个属性值对应该属性的隶属度可以被可视化为一条曲线,其值域范围为\([0,1]\)。
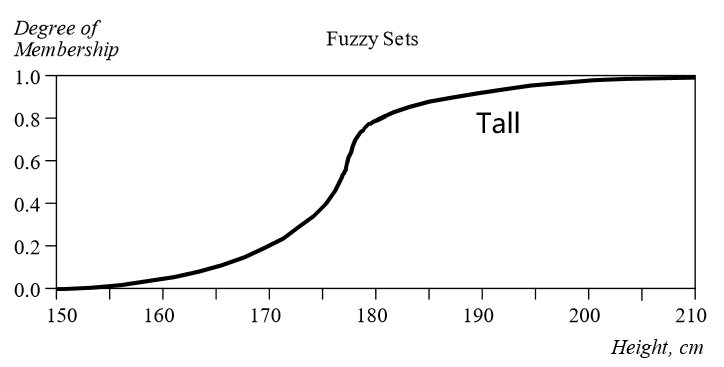
模糊逻辑的实质是通过一个映射将具体的数值映射为概率表示的隶属度,从而实现对数值的模糊化。 在模糊集论中,这个映射被称为隶属度函数(membership function)\(μ_A(x)\),表示了属性数值\(x\),称为模糊变量(fuzzy variable)与隶属某一类概率的映射关系。这样的隶属关系表示为:
\[μ_A(x)=1,x\text{ totally in }A\] \[0<μ_A(x)<1,x\text{ partially in }A\] \[μ_A(x)=0,x\text{ not in }A\]
模糊集可以由隶属度函数和模糊变量定义,用扎德表示法(Zadeh presentation)写成:
\[A=\frac{μ_A(x_i)}{x_i}+...+\frac{μ_A(x_n)}{x_n}\] 其中一个\(\frac{μ_A(x_i)}{x_i}\)称为一个单例类(singleton),它不是一个分数,表示模糊变量\(x\)的个体\(x_i\)的隶属度为\(μ_A(x_i)\)。
模糊推理
知道模糊规则中蕴涵的模糊关系后,就可以根据模糊关系和输入情况,来确定输出情况,这就叫做模糊推理(fuzzy inference)。
Mamdani模糊推理
模糊推理技术中最常用的方法是Mamdani方法。 Mandani模糊推理的过程有4步:
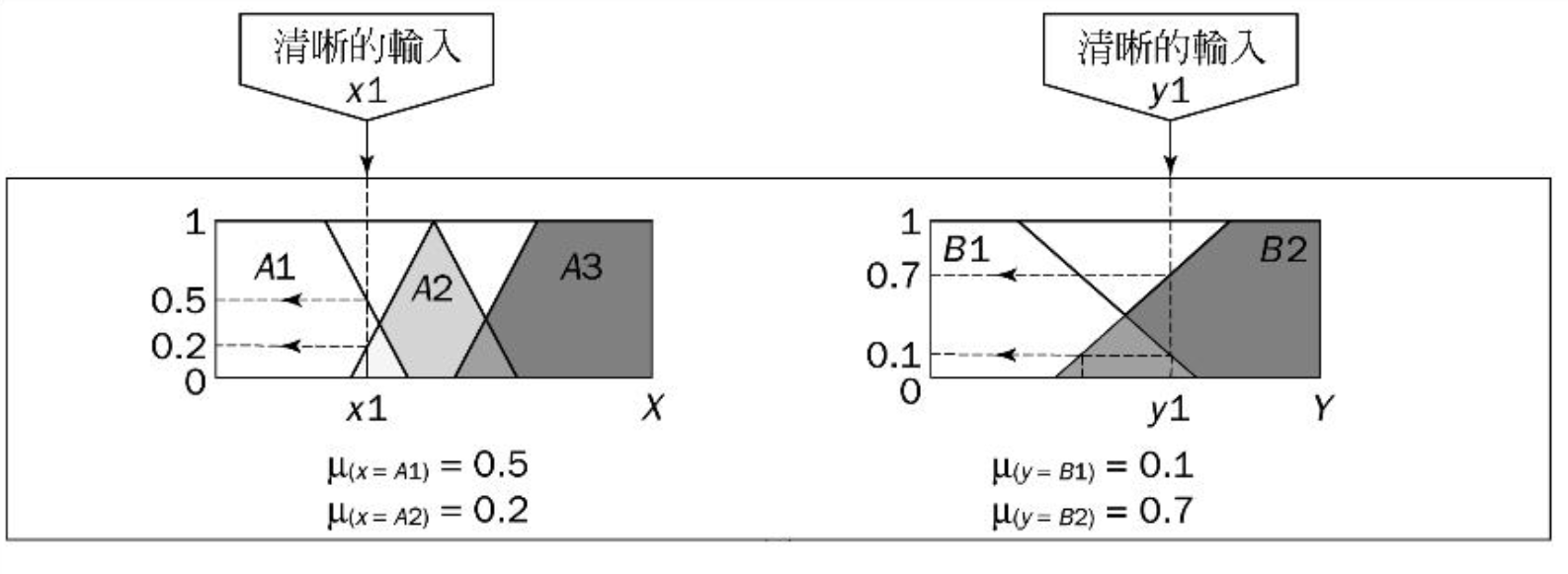
对输入变量进行模糊化
在取得精确输入\(x\)和输出\(y\)(project funding and project staffing)的前提下决定这些精确(crisp)数据属于每个适合模糊集的程度。
例如将某个精确的输入\(x_1\)和其精确输出\(y_1\)应用到如下的规则中:

得到:
评估规则
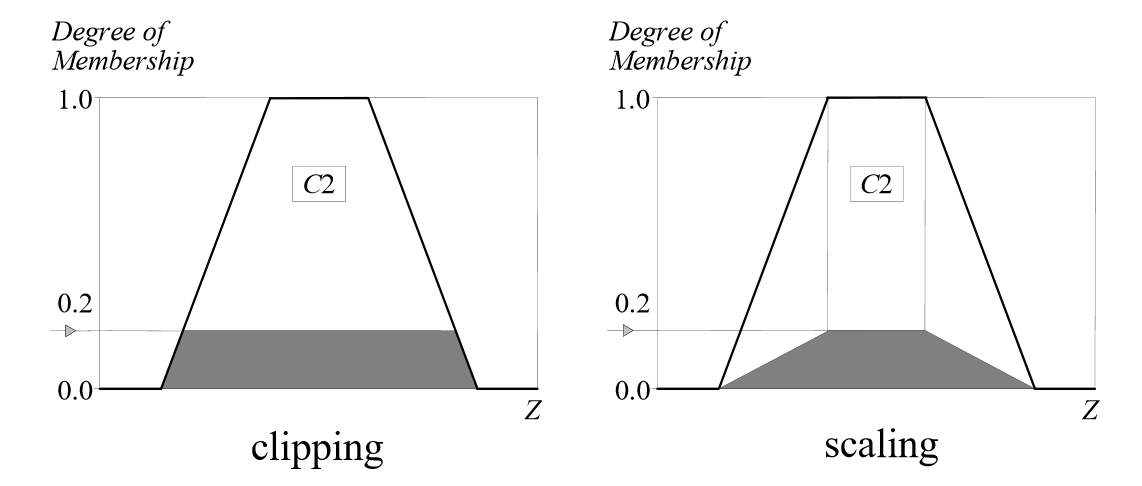
取得上一步中的模糊输入(比如例子中的:\(μ_{A_1}(x)=0.5,μ_{A_2}(x)=0.2,μ_{B_1}(x)=0.1,μ_{B_2}(x)=0.7\)),并将它们应用到模糊规则的前项(antecendents,即模糊规则中的IF表述)。如果已知的模糊规则存在多个前项,则使用逻辑关系符(AND或者OR)得到最终的一个输出值。并将得到的输出值使用α截剪切(clipping)后项对应的规则中。
除了剪切外,有时也会使用缩放(scaling)。缩放提供了保持模糊集原始形状的更好的方法。这种方法损失的信息较少,在模糊专业系统中非常有用。
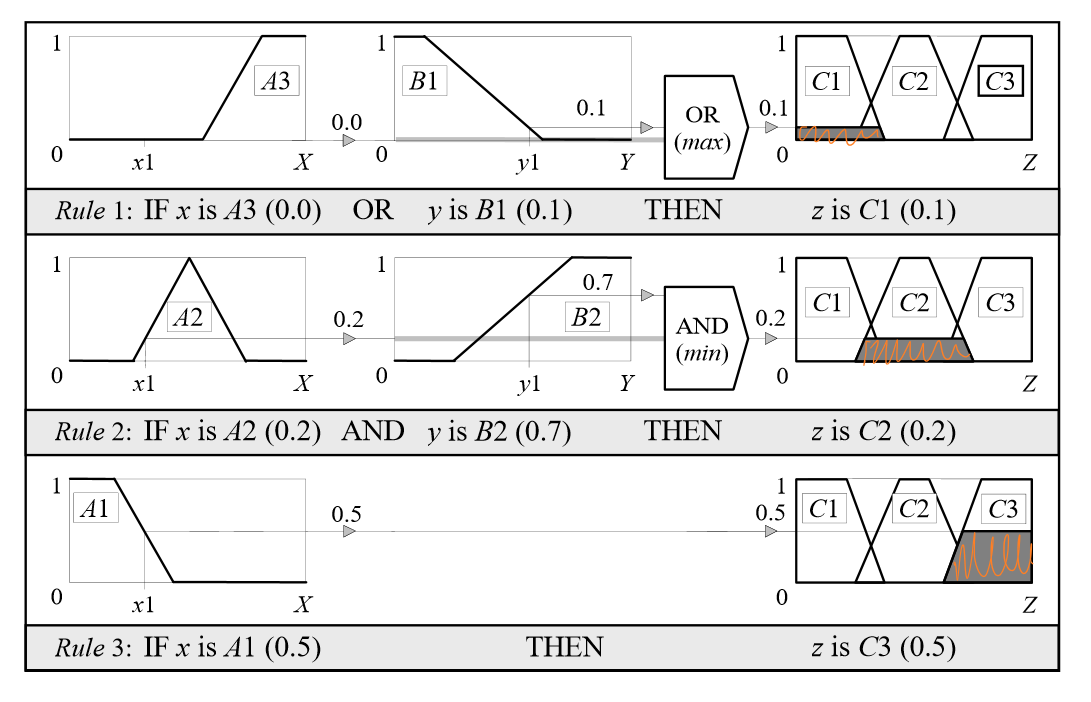
聚合规则
将剪切好的多个后项规则合并到一起,拼合后的规则称为聚合集。
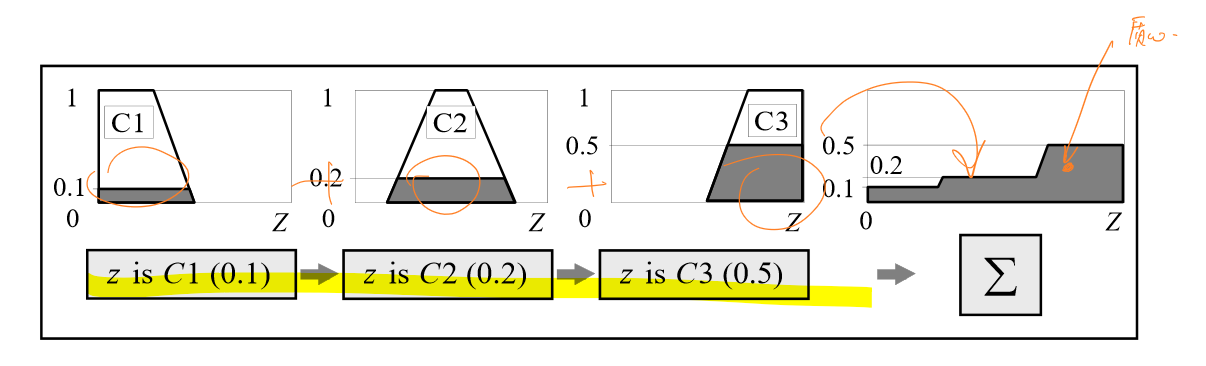
逆模糊化
模糊系统最终的输出是一个数值,因此有必要将拼合好的规则通过某种方式聚合为一个数值。常见的方法有三种:- 质心
质心表示了已知精确值对应模糊集的期望,这是最常用的逆模糊化方法。其垂线刚好可以将拼合好的规则面积分为两部分,质心的计算公式如下:
\[COG=\frac{∑xμ_A(x)dx}{∑μ_A(x)}\] - Max-in和Min-in
这两种方式表示了精确值对应模糊集的上下限,当聚合集具有多个最大值和最小值点时,有:
\[Max-in=\frac{∑Max_iμ_A(x)dx}{∑μ_A(x)}\] \[Min-in=\frac{∑Min_iμ_A(x)dx}{∑μ_A(x)}\]
- 质心
Sugeno模糊推理
Mamdani模糊推理需要通过整合连续变化的函数来逆模糊化,计算效率通常不高。而Sugeno在聚合规则时只会聚合每个规则下对应的一个单例类。整合时每个规则在该单例类下有值,其他区域的值均为0。因此Sugeno方法聚合规则并不需要聚合一个区域,只用聚合几个值即可,计算量大幅度减小。因此Sugeno模糊推理常常用于模糊神经网络(下文会详细介绍)的反向传播中。
最常用的是零阶-Sugeno模糊推理模型,它的规则表示为:
IF \(x\) IS \(A\) AND \(y\) IS \(B\)
THEN \(z\) IS \(k\)
其中\(k\)是一个常数。
在这样的规则表示下,每一个模糊规则的输出都是一个常数。所有规则的输出通过单例类表示。
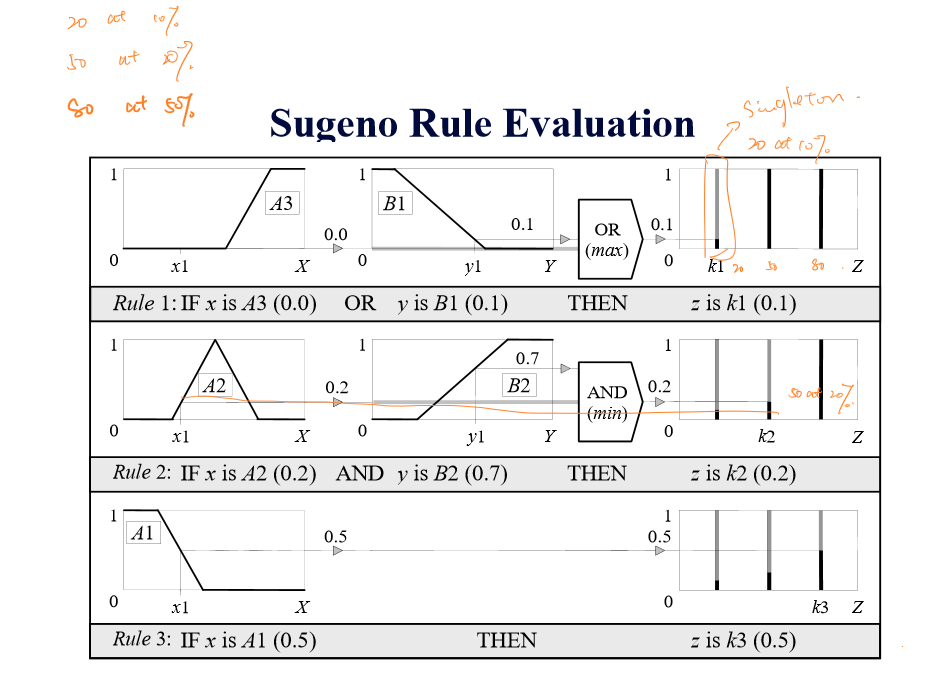
Sugeno模糊推理的第二步评估规则表示如下:
第三步聚合表示为:
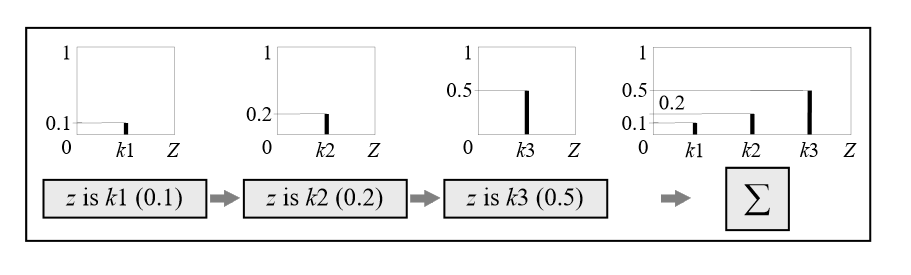
Sugeno模糊推理常常使用加权平均值来进行逆模糊化:
\[WA=\frac{∑k_i×μ_Z(K_i)}{∑μ_Z(k_i)}\]
方法评价
在获取专家知识时常常使用Mamdani方法,这种方法可以用更加直接、更加符合人类直觉的方式来描述专家的意见。但是其计算量更大。
Sugeno方法的计算效率高,可以与优化算法和自适应技术协同工作。这种方法在控制问题、尤其是在动态非线性系统研究领域比较有吸引力。
模糊运算
模糊集间的四则运算
对于两个模糊集\(A\)和\(B\),分别对应模糊变量\(X\)和\(Y\),其四则运算\(∘\)(\(∘∈\{+,-,×,÷\}\))的结果表示为:
\[\begin{aligned}
F(A∘B)=&\left[\frac{min[μ_A(x_1),μ_B(y_1)]}{x_1∘y_1}+\frac{min[μ_A(x_1),μ_B(y_2)]}{x_1∘y_2}+...+\frac{min[μ_A(x_1),μ_B(y_n)]}{x_1∘y_n}\right]\\&+\left[\frac{min[μ_A(x_2),μ_B(y_1)]}{x_2∘y_1}+...+\frac{min[μ_A(x_2),μ_B(y_n)]}{x_2∘y_n}\right]+...+\left[\frac{min[μ_A(x_n),μ_B(y_1)]}{x_n∘y_1}+...+\frac{min[μ_A(x_n),μ_B(y_n)]}{x_n∘y_n}\right]
\end{aligned}\] 简单来说即“两两配对,下面相加/减/乘/除,上面取最小”。
如果计算后存在有\(x_i∘y_j\)值相同的项,那么该\(x_i∘y_j\)值对应的隶属值为这些项中最大的隶属值:
\[μ_F(x_i∘y_j)=max\{min[μ_A(x_i),μ_B(y_j)]\}\] 下图展示了一个计算例子:
展开原则
展开原则(principle)描述了从一个模糊集\(A\)到另一个模糊集\(B\)的映射。
假设存在映射关系\(A→B:f(x)\),\(A=\frac{μ_A(x_1)}{x_1}+\frac{μ_A(x_2)}{x_2}+...+\frac{μ_A(x_n)}{x_n}\),有\(y_i=f(x_i)\),那么有:
\[B=f(A)=\frac{μ_A(x_1)}{y_1}+\frac{μ_A(x_2)}{y_2}+...+\frac{μ_A(x_n)}{y_n}\] 如果计算后存在有\(y\)值相同的项,那么该\(y\)值对应的隶属值为这些项中最大的隶属值:
\[μ_B(y)=maxμ_A(x)\]
笛卡尔积
模糊关系用于表示两个模糊变量之间的关系强度。假设模糊变量\(X\)对应模糊集\(A\),模糊变量\(Y\)对应模糊集\(B\),两者之间的关系强度可以用笛卡尔积(Cartesian Product)表示:
\[μ_{A×B}(x_i,y_j)=min(μ_A(x_i),μ_B(y_j))\] 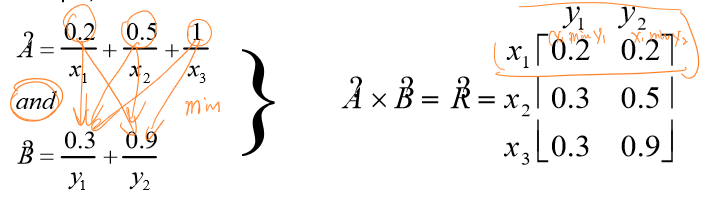
间接关系
如果模糊变量\(X\)与\(Y\)存在模糊关系\(R\),模糊变量\(Y\)与\(Z\)存在模糊关系\(S\),那么可以借助模糊变量\(Y\)推导出模糊变量\(X\)与\(Z\)的关系\(F\):
\[F=R∘S\] 其中的\(∘\)代表了两种算子:
- max-min算子
\[μ_F(x_i,z_k)=max[min(μ_R(x_i,y_j),μ_S(y_j,z_k))]\] 即关系矩阵\(R\)的每一行与关系矩阵的\(S\)每一列对应元素取最小值后再取行列计算结果中的最大值。
- max-product算子
\[μ_F(x_i,z_k)=max[μ_R(x_i,y_j)·μ_S(y_j,z_k)]\] 即关系矩阵\(R\)的每一行与关系矩阵的\(S\)每一列对应元素相乘后再取行列计算结果中的最大值。
自适应神经模糊系统
模糊推理系统非常适于表示模糊的经验和知识,但缺乏有效的学习机制;神经网络虽然具有自学习功能,却又不能很好的表达人脑的推理功能。基于自适应神经网络的模糊推理系统ANFIS(ANFIS,Adaptive Network-based Fuzzy Inference System)将二者有机的结合起来,既发挥了二者的优点,又弥补了各自的不足。自适应神经网络模糊系统其中一个十分重要的应用,就是在信号处理和控制中消除噪声或干扰。
自适应神经模糊系统只有5层结构,如下图所示:
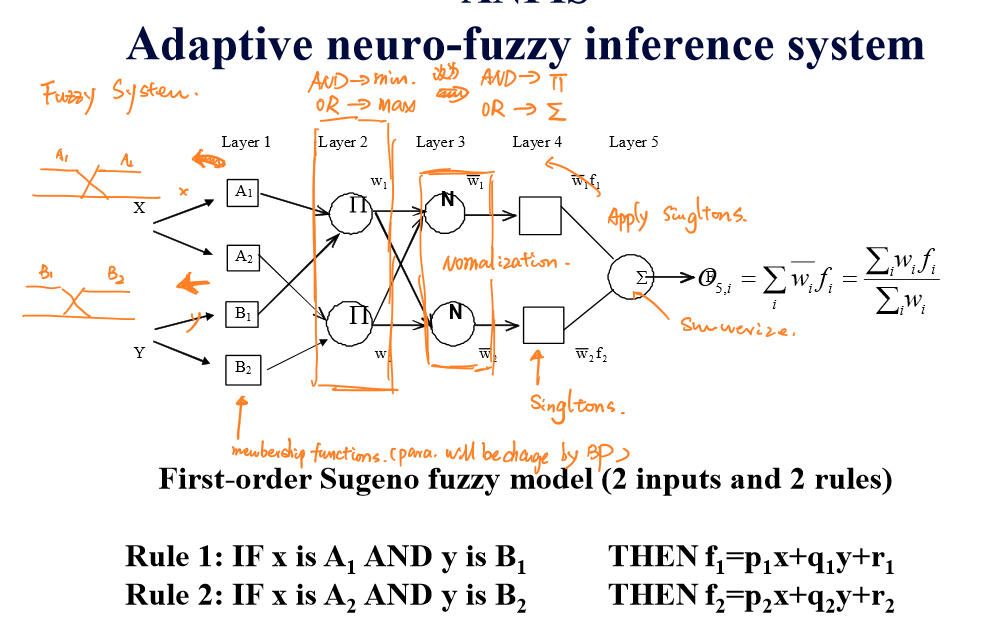
模糊层
第一层是模糊层,模糊层的每个节点带有一个隶属值函数:
\[O_{1,i}=μ_{A_i}(x),i=1,2\] \[O_{1,i}=μ_{B_i}(y),i=3,4\] 输入变量进入第一层后通过每个节点后将被各节点的隶属值函数转换为隶属值。
原始的自适应神经模糊系统第一层采用Sigmoid函数作为隶属值函数:
\[μ_A(x)=\frac{1}{1+|\frac{x-c_i}{a_i}|^{2b_i}}\] \[μ_B(y)=\frac{1}{1+|\frac{y-c_i}{a_i}|^{2b_i}}\]
运算层
这一层实现前提部分的模糊集的运算。在这一层中的每个结点都是固定结点,它的输出是所有输入信号的代数积。
每个结点的输出表示一条规则的激励强度,本层的结点函数还可以采用取小、有界积或强积的形式。通常采用AND运算。
\[O_{2,i}=∏_{j=1}^nμ(x_j)=w_i\]
归一化层
第三层将第二层的输出\(w_i\)进行和归一化处理:
\[O_{3,i}= \overline{w_i} =\frac{w_i}{∑_jw_j}\]
结果层
这一层将归一化的权重应用到结合的单例项\(f_i\)中:
\[O_{4,i}=\overline{w_i}f_i=\overline{w_i}(p_ix+q_iy+r_i)\] 其中的两个单例项合并的结果:\(p_ix+q_iy+r_i\)中的系数需要通过反向传播找到。
逆模糊层
第五层是输出层,其将第四层的输出进行逆模糊化。逆模糊化的方法常常采用质心:
\[\hat{F}=O_{5,i}=∑_i\overline{w_i}f_i=\frac{∑_iw_if_i}{\sum_iw_i}\]
反向传播*
自适应神经模糊系统的学习过程同样使用了基于梯度下降的反向传播。这是一种监督学习方法。
在ANIFS中,真实值和预测值的差表示为: \[δ=(\hat{F}-F)^2\] 其中\(F\)为真实值。
ANIFS系统中的参数\(a\)、\(b\)、\(c\)的更新公式为:
\[a:=a-η\frac{∂δ}{∂a}\] 输出层的梯度表示为:
\[δ_o=\frac{∂δ}{∂(x,y,...)}\]
遗传算法
本章节的具体内容可以参考网站中全部有关于遗传算法的部分,这里只列出了智能系统设计课程对于遗传算法要求掌握的知识点。
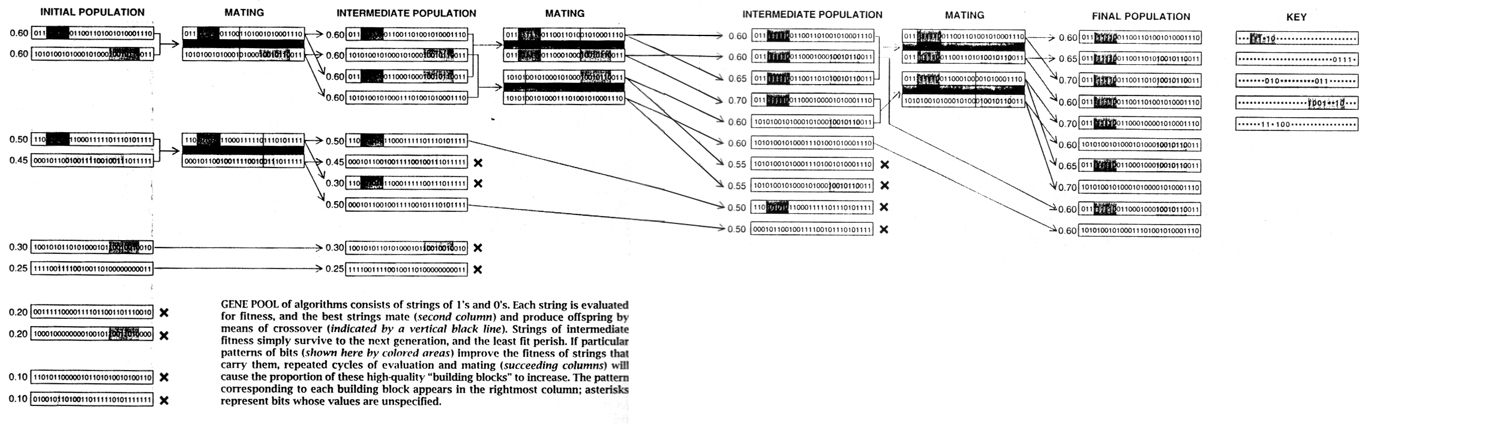
遗传算法(genetic algorithm)是一类将特定问题潜在的解决方案编码,然后应用进化理论对解决方案进行优胜劣汰式的反复筛选的算法。
算法流程
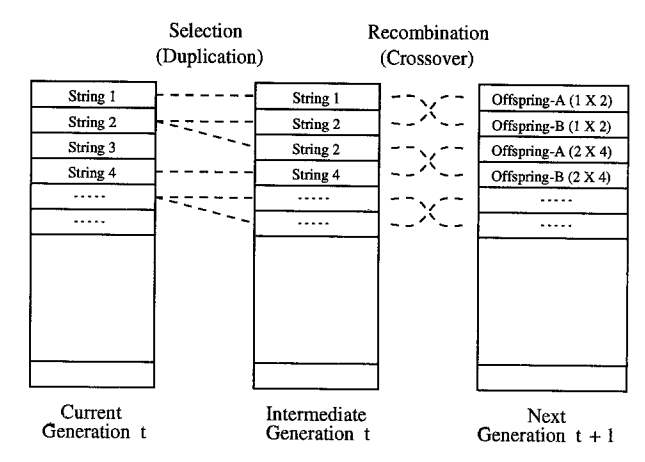
经典遗传算法通过对当前种群的评估(evaluation),选择(selection),重组(recombination)和突变(mutation) 后,能够在现有种群的基础上产生下一代种群。
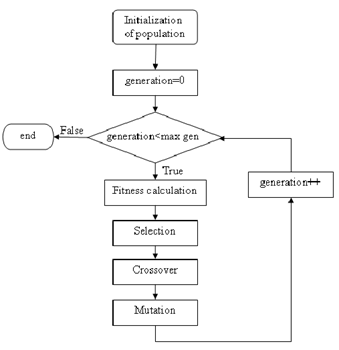
原始种群(initial population)
在遗传算法中,定义种群中编码后的一条固定长度为L的字节串称为一个个体,这样的个体称为基因型(genotype)或者是染色体(chromosome)。 在大多数情况下,原始种群被随机的产生出来。
> 此处的随机指在空间内随机的取出一些编码的组合(当然也受制于编码机制等)。
评估和适应度
原始种群被生成后,每一个个体会通过评估函数和适应度函数(Fitness funtion)生成其对种群的适应度(fitness),从而量化每个个体的表现优劣:
\[F(x_i)=f_i\] 其中\(F(·)\)是适应度函数,\(x_i\)是一个个体。
适应度函数的选择可以是个体表现越好,其适应度越高;也可以是个体表现越好,适应度越低。常见的适应度函数是均方差函数。
种群中个体\(i\)的适应度定义为:
\[\frac{f_i}{\overline{f}}\]
其中,\(f_i\)表示评估函数对第\(i\)个个体的评估结果,\(\overline{f}\)表示种群的平均评估。
选择
定义在现种群经过选择后保留的种群称为中间种(Imermediate population),中间种经过突变和重组后会成为下一代种群。
在遗传算法中,选择的本质是概率性地将现种群中的个体进行复制,最终得到中间种的过程。
选择机制有非常多种,其中最为常见的是轮盘赌(Roulette wheel)和余数随机采样(Reminder stochastic sampling).
- 轮盘赌
如果整个轮盘表示整个种群,每个个体所占面积与适应度成正比,每一次转动就能随机地抽取一个个体复制,更高效的办法是轮盘外围上均匀地分布着N个均等间距的指针,每一次转动就能随机抽取N个个体进行复制。 经过若干次转动后,结果的集合构成中间种。
- 余数随机采样
具体而言,对于适应度大于1的个体,适应度的整数部分表示该个体会被复制多少次。对所有的个体,适应度的小数部分表示额外被复制的概率。 比如,适应度2.3的个体能够获得2次复制,并且有0.3的概率能获得第三次复制的机会。
重组
遗传算法依赖于重组来挖掘新的潜在个体,其本质是通过部分交换两个个体的信息来有概率地继承两个个体中有用的信息,抛弃两个个体中无用的信息。
- 单点交叉(single crossover)
单点交叉的过程主要有两步:- 随机地使得个体间两两配对。
- 随机地选取一对个体,两者在某个随机且相同的比特位处断开,前后的两段基因型进行交叉互换。
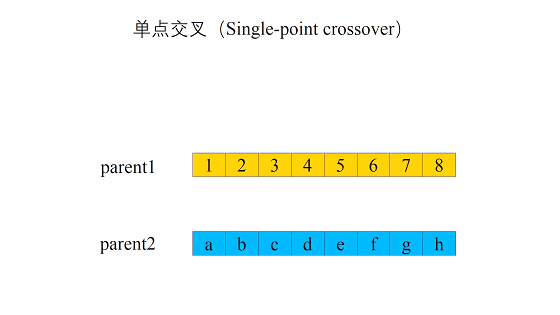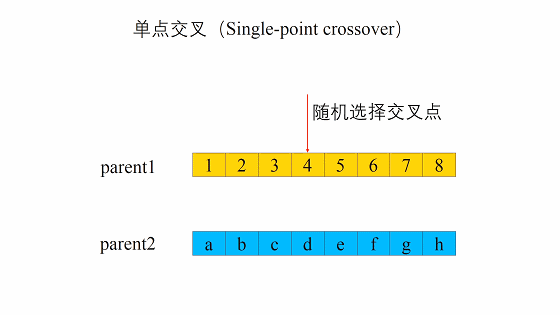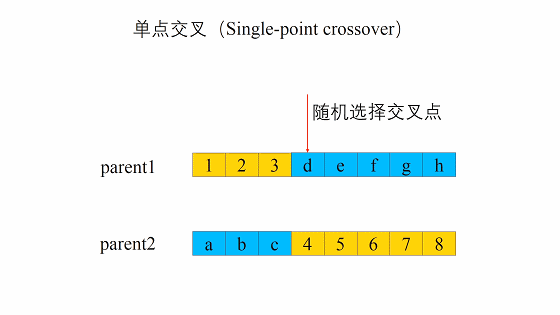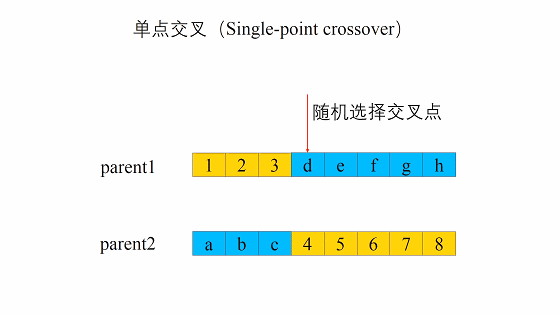
- 随机地使得个体间两两配对。
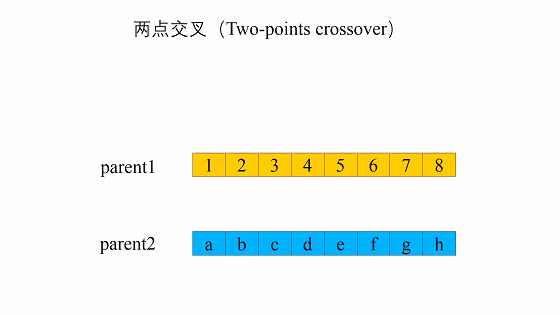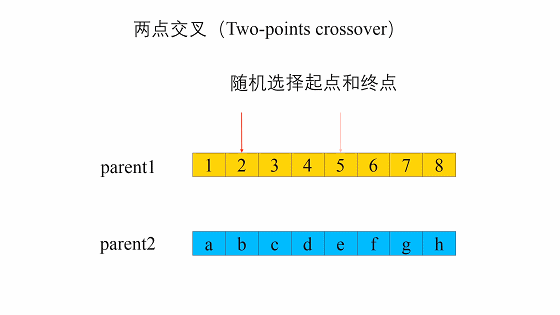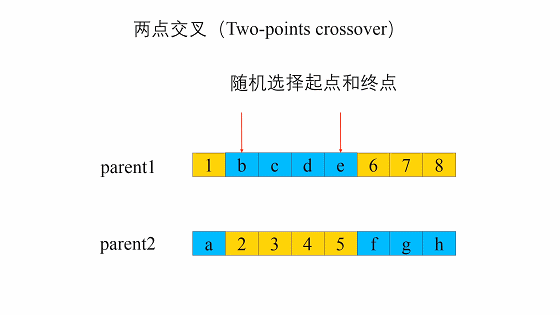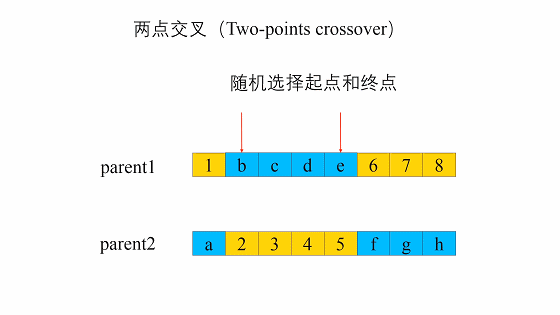
- 两点交叉(two-point crossover)
两点交叉是指在个体染色体中随机设置了两个交叉点,然后再进行部分基因交换。两点交叉的具体操作过程是:- 在相互配对的两个个体编码串中随机设置两个交叉点;
- 交换两个个体在所设定的两个交叉点之间的部分染色体。
- 在相互配对的两个个体编码串中随机设置两个交叉点;
新生成的两个个体称为后代(Offspring),后代能够插入到下一代的概率计作\(p_c\)。
突变
重组之后利用突变算子对后代作突变(mutation)处理,突变的作用是在进化过程中为当前种群随机地施加干扰,增大选择压力,防止遗传算法陷入局部最优解。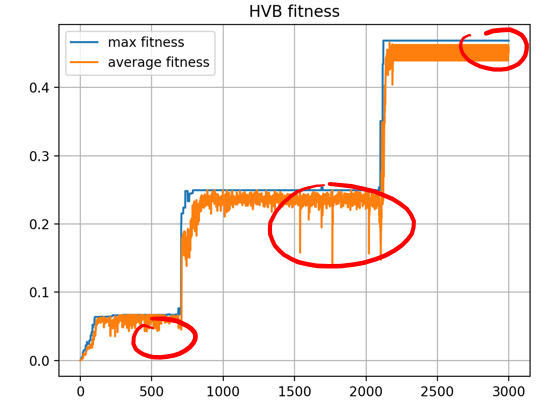
比如上图中红圈的位置表明了遗传算法通过突变经历了两次跳出局部最优解的过程,最终达到全局最优解。
对于种群中的所有比特位,其突变的概率计作\(p_m\),这是一个非常小的值,通常小于1%。 突变有可能随机地产生一些比特(并且有50%的可能性改变原本的比特值),也有可能反转原有的比特(一定能改变原本的比特值)。
中间种经过重组和突变,最终能称为新的种群。
伪代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18Input: pop_size, pc, pm, dataset
Output: best solution
Begin
i=0;
set pop_size, pc, pm;
initialize M(0) with pop_size;
while (not terminal condition) do
M_f(i) = evaluate M(i);
inter_M(i) = select M(i) with M_f(i);
\\注:evaluation和selection可以放在循环最后或者最前
random_pair inter_M(i);
M_c(i) = crossover inter_M(i) with pc;
M_m(i) = mutation M_c(i) with pm;
i = i + 1;
end
output best solution;
End
遗传算法中的设置
超参数设置
遗传算法中的超参数有三个:初始种群大小、重组概率和突变概率。
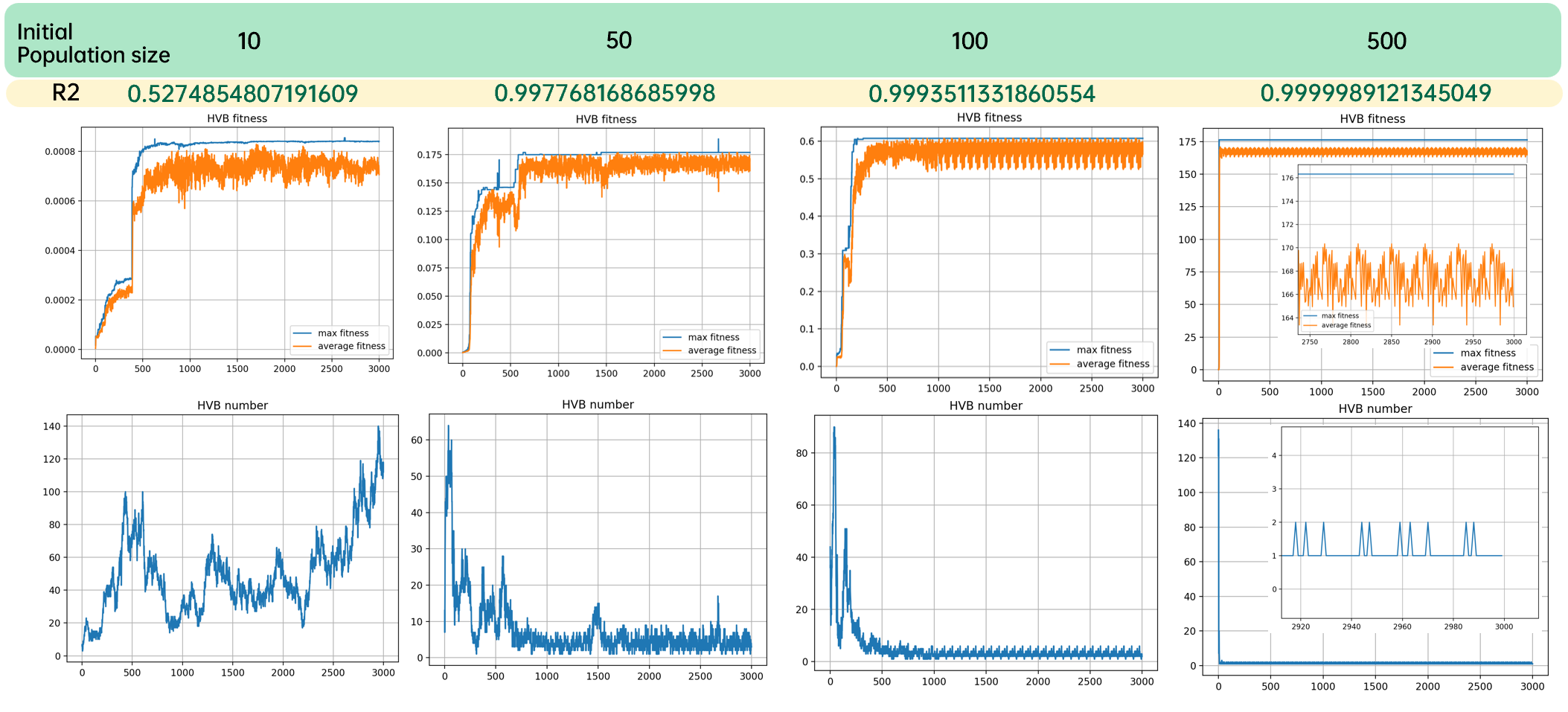
初始种群大小
初始种群大小的典型值在100左右,过小的初始种群大小会使算法的收敛速度减慢,而过大的初始种群大小会使得计算量成倍增长。
重组概率
由于遗传算法依赖于重组来挖掘新的潜在个体,因此一般认为,重组概率应当设置的相对大一些,才能不断地寻找新个体,典型值在0.5-1。
过小的重组概率使得非常容易算法无法找到全局最优解就提前收敛,而过大的重组概率会使得算法持续振荡而无法收敛。突变概率
文献中通常认为突变存在消极和积极两方面的影响,所谓积极是指算法可以通过突变跳出局部最优解;但是与此同时,突变也会破坏掉原本找到的有用信息——这是突变消极的一面。因此,突变的概率应当设置的相对小一些,才能保证对现有种群的干扰是微小的,不会破坏现在已经查找到的有用信息,突变概率的典型值在0.005-0.05。
过小的突变概率使得非常容易算法无法找到全局最优解就提前收敛,而过大的突变概率会使得遗传算法因为无法继承有用信息而退化为随机搜索。
终止条件
遗传算法的在何时收敛是目前学界研究的一个重要问题,与神经网络不同,倘若不设置任何条件,在某些超参数的设置下遗传算法可以一直运行下去,因此遗传算法往往需要人为地添加终止条件,强制终止算法的运行,通常使用的终止条件有:
- 当前种群中有个体的适应度达到了设置的阈值标准,比如均方差小于某个数值。
- CPU的运行时间(elapsed times)。
- 当前种群的平均适应度不发生明显变化。
- 算法运行的代数达到设置的阈值,比如算法运行3000代后自动停止。
- 对于种群大小不固定的进化策略,当前种群中的个体数量小于某个阈值,比如个体数量只有一个时由于无法进行交叉而自动停止。
选择机制
选择机制是指如何选择个体进行交叉和突变等遗传操作。选择策略除了上文中介绍过的轮盘赌和余数随机抽样之外,还有排名算法和锦标赛算法。
轮盘赌/余数随机抽样
这两种方法的优点是都是基于概率的随机抽样,因此,适应度较低的个体也有可能被选择进行遗传操作,这样的好处是适应度较低的个体中仍然具有少量有用信息,概率抽样可以利用这些信息可以帮助收敛到全局最优;缺点是适应度较低的个体中的无用信息在进行遗传操作时可能破坏其他个体的有用信息;对于轮盘赌选择,当适应度值差别很大时,极优秀的个体会在轮盘上占据相当大的面积,导致其他个体被选择的概率很低,陷入局部最优解。排序算法(rank)
将选择概率依据适应度排名重新分配给每个个体。比如如下的例子:
设三个个体的适应度评估为:\(h_1,h_2,h_3\).首先对所有个体按照适应度从小到大排序,比如:\(h_2,h_1,h_3\); 按照上面的顺序重新赋予适应度,即\(f(h_2)=1,f(h_1)=2,f(h_3)=3\),计算选择概率:\(p(h_2)=\frac{1}{1+2+3}=\frac{1}{6},p(h_1)=\frac{2}{6},p(h_3)=\frac{3}{6}\)。
排序算法的优点是由于取消了适应度和选择概率的直接关系,当前种群中适应度极大的个体不会完全占据进化的主导优势,避免算法迅速陷入局部最优解。锦标赛算法(tournament)
将整个种群分为\(K\)组,每组内部选择适应度最好的一个或者几个个体加入到下一组。锦标赛算法为遗传算法提供了并行计算的可能性。
繁殖策略
繁殖策略是指决定哪些个体可以进入到下一代的策略,主要有两种:
- Generational策略
经典GA中所使用的策略,即不保留亲本,经过选择后的亲本通过交叉和突变直接生成下一代个体。
Generational策略的优点是进化速度快,但是由于不保留亲本,因此亲本中的有用信息可能被丢失。
- 稳态策略(steady-state)
亲本和子代按比例加入到下一代,通常是50%:50%,这样的好处是亲本的信息被完全保留,但是进化速度较慢。
- 精英策略(elite)
总是将当前适应度最好的一个或者多个个体保存到下一代。