EventiC——一种无偏的复杂系统实时事件建模器
本文最后更新于 2025年9月1日 上午
EventiC——一种无偏置的复杂系统实时事件建模器
EventiC:A Real-Time Unbiased Event-Based Learning Techique for Complex Systems. Morad Danishvar, et al. 2018. IEEE Transactions On Systems Man and Cybernetics:Systems.
【ROC算法的执行过程图】User Behaviour-driven Group Formation through Case-based Reasoning and Clustering, Ella Haig, et al. 2012, Expert Systems with Applications.
EventiC 提出了一种对于实时物理系统建模的方法。当设定好关心的事件后,其通过对离散事件系统进行采样、过滤,然后应用ROC聚类算法对所关心的事件发生的触发进行聚类,从而找到触发与事件的关联性。
问题动机
对于复杂控制系统建模,传统的建模方法依赖于非线性或者是线性的微分方程来描述控制系统的行为,这种方法需要对系统的输入变量、以及每个输入变量对系统的影响因素有着充分的了解。换句话说,传统的复杂控制系统建模具有高度的经验依赖性。第二,在系统中实时地对模型评估和验证准确性和正确性会浪费大量的时间和财力。对于传统的数据建模方法,其将系统的状态变量\(V_n=[x_1,...,x_n]\)表示为一组关于输出的复杂信息。随后的对于状态变量的操作都是基于一个假设——这个状态变量一定与已知的系统输出相关,本论文中称为“真实表现(true presentation)”。而本文所提出来的EventiC不需要基于这样的假设,即所获得的数据不一定与系统的输出产生关联,这个关联性是通过EventiC的处理过程得到的。
现有解决方案
简单来说,系统建模的方法即是寻找系统输入和输出之间的关系。系统输入对每个输出的影响。描述系统输入在其发生时对每个输出的影响的方法在工程领域一般被称为IVS,在数学领域被称为灵敏度。现阶段,灵敏度或者是IVS可以由如下表所示的几种方法得到。
| 方法 | 过程 | 案例 | 缺点 |
|---|---|---|---|
| 分析和数学方法 | 通过数学公式描绘出系统变量所造成的影响 | 微分方程 格林公式 |
过于理想化,大多数的建模只适用于LTI系统,无法处理更为复杂的非线性系统以及含有相关性强的系统变量的系统 |
| 基于采样的方法 | 基于大量对系统真实输入和输出的采样和测量结果找到输入和输出之间的关系 | 基于熵的认知 蒙特卡罗方法 拉丁超立方抽样 |
依据历史数据,可靠性受限于采样数和对数据关系的表达 计算量通常非常大 |
| 启发式算法 | 基于系统专家的经验,使用一些机制对搜索空间进行高效查找 | 遗传算法 | 优化目标与系统专家的经验设置有强烈的关系 需要根据系统专家的经验定义适应度、历史趋势等等 |
除了上述三种方法外,还有一种寻找系统输入和输出关系的方法,称为事件聚类(Event clustering)。事件聚类不依赖于任何有关对于数据关系的预设(比如判断好坏等等),从这个方面来说,这是一种无偏的(unbiased)方法。
事件聚类基于的前提条件是可以通过改变输入变量的状态将这个系统的状态分解为若干个离散的事件。
聚类是一种无监督或半监督学习方法,聚类算法的效果受到三个方面的影响:数据量、实时系统数据流的速率、数据的种类。早期的一些文献发现ROC聚类算法(Rank Order Clustering)在对实时系统数据的处理中表现出一定潜能。面对大而广泛的数据时,ROC聚类算法表现出了极高的高效性和有效性。EventiC中使用了这一方法。
EventiC的方法论
定义
事件
在复杂控制系统中,任何一个系统状态的变化称为一个事件(event).
离散事件系统
离散事件系统(discret event system)指在一定时间限度内中事件的发生是离散的系统。换句话说,事件之间出现的的间隔在整个观测期内是十分明显的。
触发数据和事件数据
一组其本身改变可以引起事件发生的输入变量称为一组触发(trigger),它们的值组成了触发数据(TD, trigger data)。
一组可以表现任何时间下系统状态的数据称为事件数据(ED, event data)。
触发阈值和事件阈值
简单来说即是分别对触发和事件设定的关心值:当触发数据或者是事件数据达到了设定好的这个阈值,才对这些触发和事件进行分析,否则忽略。
比如如果只关心生产效率在90%以上的事件,那么事件阈值即为90%。
触发阈值和事件阈值都需要由系统专家进行设定。
运行条件
EventiC的作用条件基于如下的三个假设:
- 触发是及时的。也就是说系统会立即对一个触发产生响应并生成一个事件。换言之,触发和时间之间的时间差可以忽略不计。
- 要考虑的触发和事件阈值由系统专家预先设定,以避免“出生体重悖论”(birth-weight paradox)。换言之,触发和事件之间必须具有因果性,这个因果性依赖于人类经验保证。
此处对避免“出生体重悖论”的机制存疑。
- 触发和事件是同质的(homogenous),异质的(heterogeneous)系统参数必须要以某种方式转化为同质的事件。即用同样的方法处理触发数据和事件数据对两者的作用相同,触发数据和事件数据的信息密度需要保持在同一个水平。
运行过程
EventiC的过程可以简述为三步:
- 在既定的事件粒度下描述输入和输出的变化
- 探测输入和输出事件的发生
- 将相关的输入和输出事件进行聚类
触发和事件的设定
在正式运行EventiC之前,必须要设定好触发和事件的粒度,即描述观测系统的宏观或者是微观的程度。当系统的输入或者输出产生“明显”差异时,认为系统产生了触发或者事件。“明显”的程度通过两个阈值\(θ\)和\(Φ\)来规定(注意此处的阈值并不是触发阈值和事件阈值),定义\(t\)时刻的系统是触发和事件:
\[\begin{cases}
\text{if } Input_t-Input_{t-1}≥θ→TD_t\\
\text{if } Output_t-Output_{t-1}≥Φ→ED_t\\
\end{cases}\]
上述公式可以简单理解为“量变引起质变”:
如果检测到触发产生,那么\(TD_t=1\),否则为0;如果检测到事件发生,那么\(ED_t=1\),否则为0。
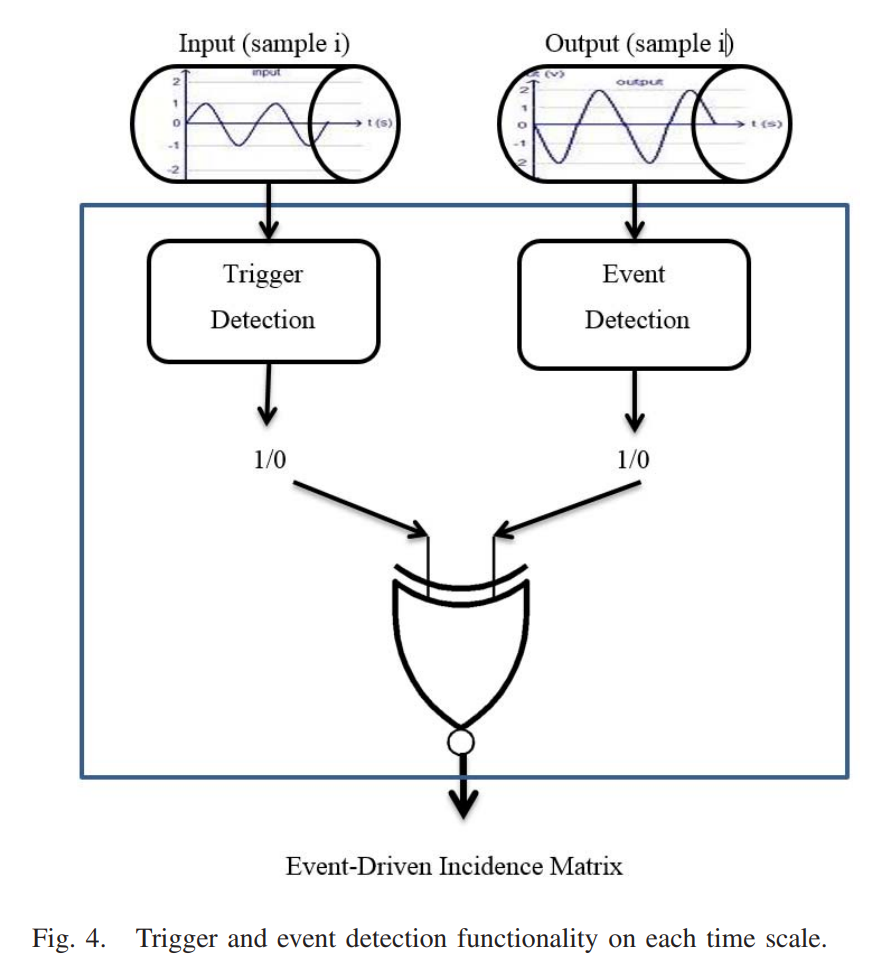
采样
对整个系统进行实时采样,采样率和采样数(用于建立相关矩阵的采样个数)由系统专家确定,通常采样值的下限是250。
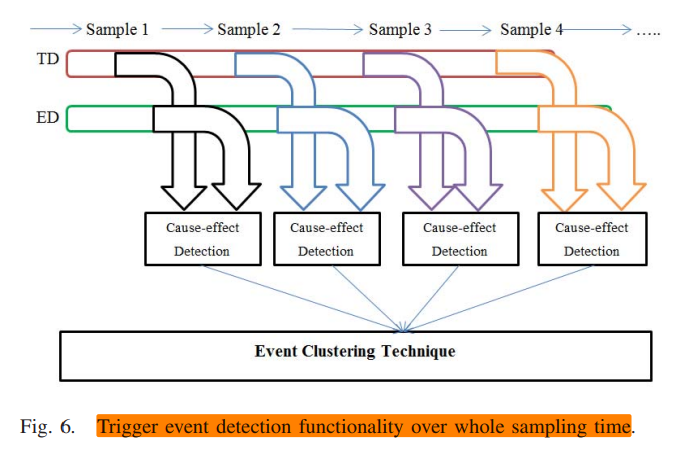
ROC聚类算法
对于ROC聚类算法,其首先会对每一次采样建立一个相关/混淆矩阵(incidance matrix/confusion matrix),其行表示每一个触发数据,其列表示每一个事件数据。对于矩阵当中的每一个元素\(a_{ij}\),表示为对应行\(i\)(触发)和对应列\(j\)(事件)的同或(XNOR):
\[a_{ij}=[TD_{i}]XNOR[ED_j]\] 对于同或,其行为简述为“相同为1,不同为0”,也就是说,只有当某个触发和某个事件都发生或者都不发生时,混淆矩阵中的对应元素才为1——这体现了触发与事件的相关性。
紧接着,进入如下的迭代过程:
- 对每一行都赋予一个二进制权重\(BW_i=2^{m-j}\),对于每一行/每个触发,计算出一个评分/十进制表示\(DE_i\):
\[DE_i=∑_{j=1}^m2^{m-j}a_{ij}\] - 检查现在行从上到下位置是否和评分排序相同,如果是,则停止算法。如果不是,则进入3.
- 将每一行按照对应的评分从大到小排列。
对列也进行相同的操作:对每一列都赋予一个二进制权重\(BW_j\),对于每一行/每个触发,计算出一个评分\(DE_j\):
\[DE_j=∑_{i=1}^m2^{m-i}a_{ij}\] - 检查现在行从上到下位置是否和评分排序相同,如果是,则停止算法。如果不是,则每一列按照对应的评分从大到小排列后返回1。
一个ROC的例子如下图所示:
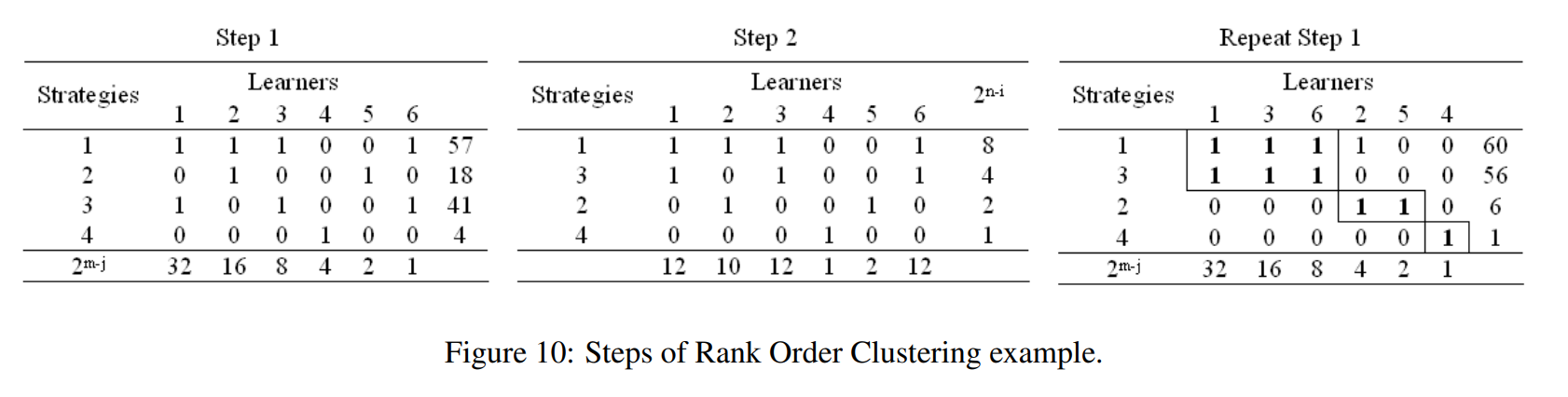
如此,整个相关矩阵被化简为一个对角矩阵。如下图中的例子:
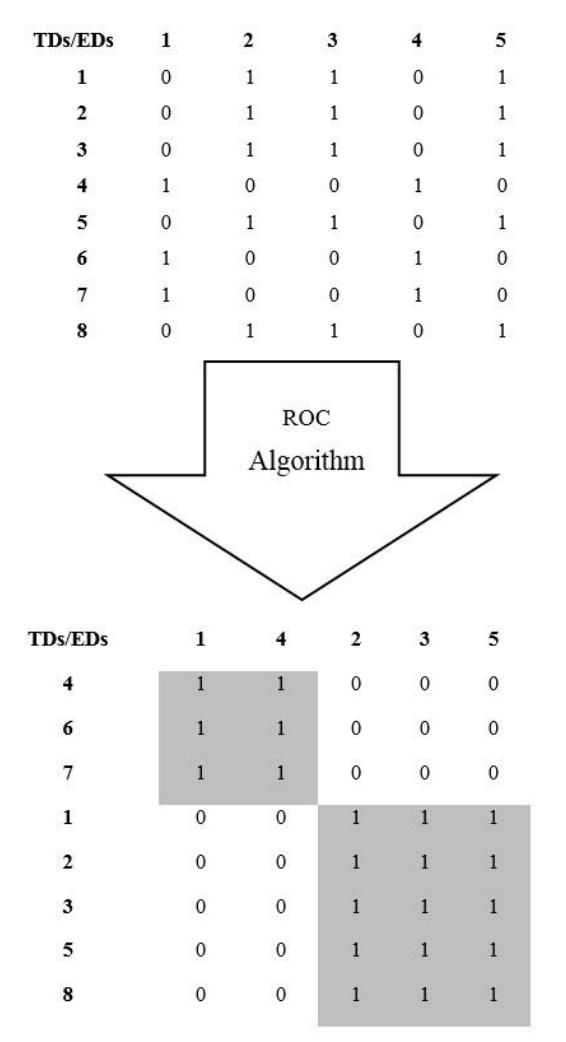
如上图,可以发现,触发4/6/7和事件1/4的发生有着明显的关联性。触发2/3/5/8与事件2/3/5的发生有明显的关联性。
计算灵敏度
每一个输入对输出参数的平均灵敏度通过某种机制被计算出来,灵敏度可以理解为表示某个事件对某个触发的灵敏程度。并根据在总采样中该触发在该事件发生下的发生频率/概率对每一个触发的灵敏度进行加权处理。
灵敏度的计算方式有多种,根据具体问题进行具体选择,详见灵敏度分析方法一讲。
过滤
让每一个触发通过一个基于触发阈值的过滤器,以过滤出对某一事件关系很大的触发,以具体分析这些触发的灵敏度事件的相关性。
复现
找到了与事件相关的触发之后,可以通过回溯达到事件阈值时的触发参数配置,对达到事件阈值时的事件进行复现。
应用案例:水泥烧块生产
水泥生产中最重要的一个环节是水泥烧块/熟料(clinker)的生产:其需要将湿生料(damp rawmix nodules)放入工业炉预热器(lepol grate preheater)通过热气进行预加热后,送入窑(kiln)中进行烧制,最终通过冷却形成水泥熟料,整个过程如下图所示:
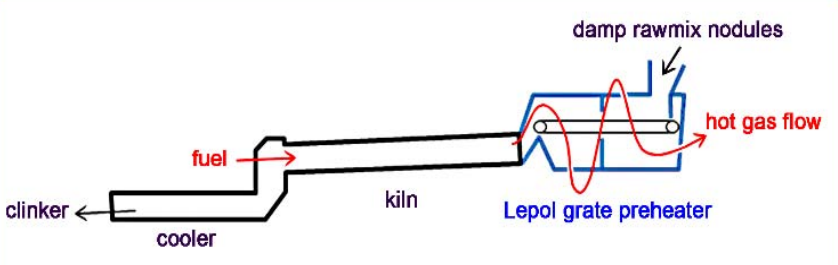
整个系统中产生的源数据通过SCADA系统(一种工业控制系统)获得,输出数据通过在输出端设置好的计数器和传感器获得,EventiC将对应的参数和输出数据转换成触发和事件,此处,考虑的事件有有三个:产率(吨/小时)、二氧化碳排放量和能量消耗。在这个系统中EventiC的采样率为SCADA系统的采样率,为每分钟一次。
第二步,对每一个采样都建立一个ROC矩阵,并根据ROC矩阵分别计算每一个触发对这三个事件的灵敏度。
设置一个触发阈值,描述对触发事件的关心程度,此处设置对产率为90%,对产率的灵敏度低于90%的触发被过滤掉。
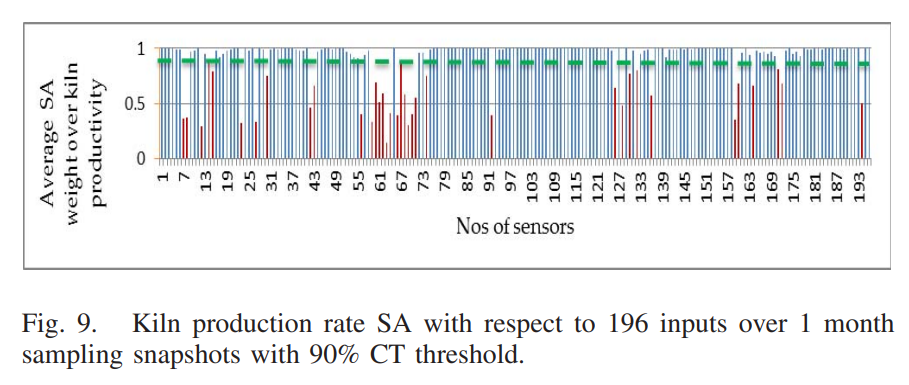
根据灵敏度,在193个系统触发中,有36个触发被过滤掉,留下82%的触发继续进行分析。下表列出了9个最关键的输入:
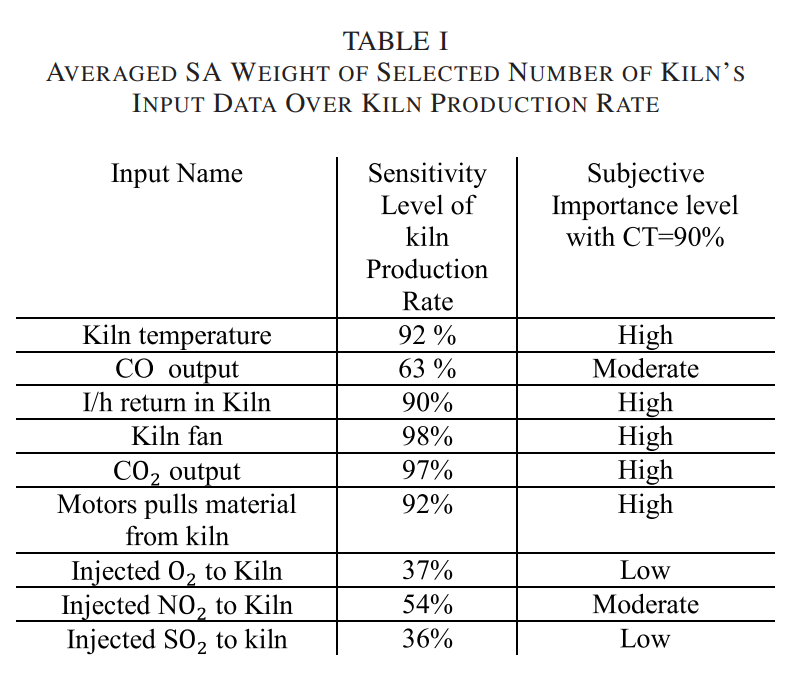
可以发现最相关的/敏感度最高的5个指标分别是:窑内温度、窑内的风扇开关、二氧化碳排放量、倒入生料的马达转速、I/h return of kiln.
紧接着,对采样应用事件阈值,过滤出所关心的事件,并提取出这些采样时刻的相关触发的参数配置,例如:在42001次采样中,提取出产率最高的5次采样:9.68-9.76吨/小时,如下图所示:
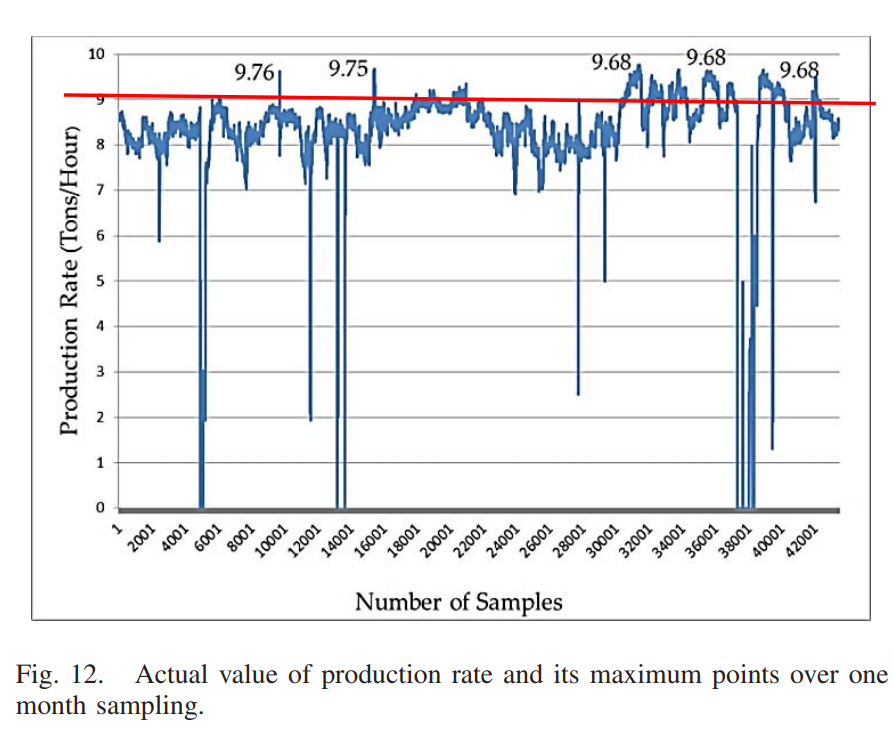
回溯这五次采样相关的指标参数:
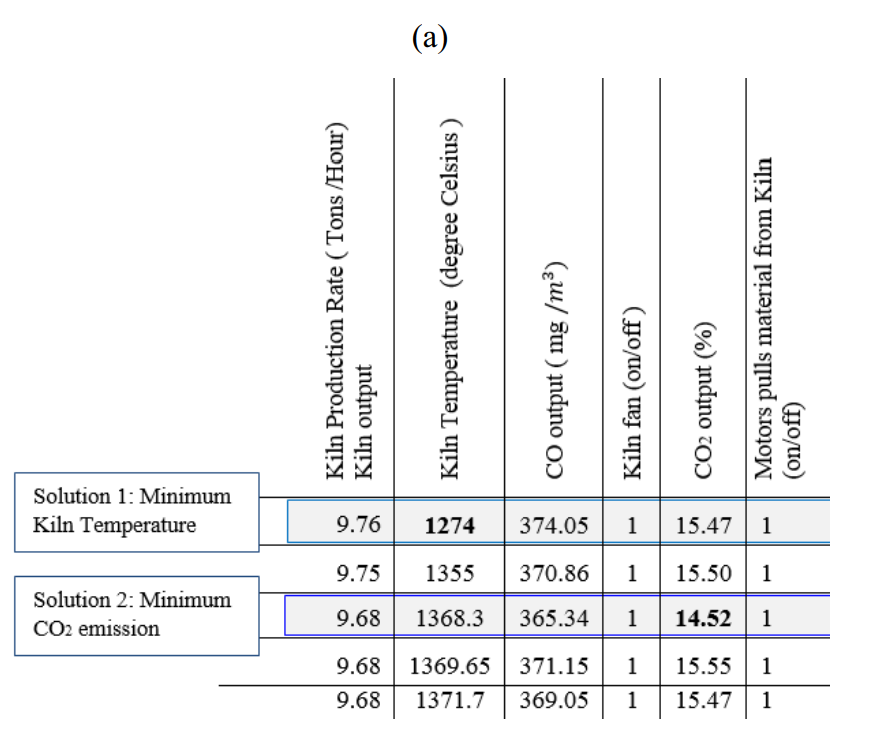
根据这五次采样相关指标的参数,可以决定后续系统的参数配置。也可以在如上图所示,在最优的产率下寻找最小窑温度或者最小二氧化碳排放量的参数配置,起到综合考量的效果。
评价
EventiC通过实时采样和分析可以对系统进行实时聚类,通过聚类结果可以找到系统在期望状态下的参数配置,并进行复现。而期望状态可以很方便地通过设置不同的事件阈值对其进行过滤,或者设置多维度的滤波器以从多个方面对系统的“最佳状态”进行考量。其二,由于没有假设输入和输出之间必然具有相关性(无偏的),通过对触发事件合理的设置,EventiC可以发现容易忽略的引起系统改变的触发,例如在本文中发现了倒料口马达的转速与熟料产生产率有着直接关系,这个结果在土木类文献当中是从未有过的记录。此外,ROC聚类算法本身的计算量比较小,易于在工程中应用。
EventiC的缺点是,其本质上仍然是基于历史数据的一种查找和聚类方式,通过回溯历史上出现的最高点对应的参数设置对系统未必可以进行完美复现,这是EventiC的局限性。
疑问和讨论
- 权重是如何被赋予的,灵敏度是如何被计算的?
- 权重的赋予按照下图所示:
- 灵敏度计算需要根据不同的场合选取计算方式,详见灵敏度分析方法一讲。
- 权重的赋予按照下图所示:
- 在EventiC中,新生儿低体重悖论是如何被避免的?
- 采样后对事件进行过滤再应用ROC算法对过滤后的事件进行处理,而非如文中对每一个采样先进行ROC聚类,再应用事件阈值进行过滤。这样可以进一步减小计算量。
- 可以通过EventiC寻找相关变量,应用遗传算法或者GEP算法,将相关变量转化为基因,对数据进行深度挖掘或许可以避免EventiC的局限性。
- 模式识别中,或许可以通过挖掘数据集,用EventiC寻找与识别结果高度相关的识别特征,将这些特征通过GA/GEP算法模拟产生新的个体,从而实现对数据集的扩增。
我认为,现阶段EventiC还存在两个问题:
- 灵敏度分析的问题
本文中并不强调灵敏度分析这个概念,事实上,灵敏度分析带来的计算量和时间成本并没有在本文中得到考虑。
- 基于差分的触发事件的问题
基于差分的事件/触发存在一个巨大的问题——对系统变量和输出的关联程度表现并不完整,由于差分分析只依赖于相邻的两个数据点,无法感知变量整体对系统整体的贡献程度,因此表现不佳。