结构变换操作
本文最后更新于 2025年9月1日 上午
结构变换操作
John R. Koza, Evolving the Architecture of a Multi-Part Program in Genetic Programming Using Architecure-Altering Operations, 1994.
在自然界中,基因重复(gene duplication)是一种非法的基因重组行为,它将导致单挑染色体上的一段较长的核苷酸子序列发生重复。遗传学家大野干(Ōno Susumu)在《Evolution by Gene Duplication》中提出,基因重复是进化的动力。
重复的基因会导致基因体额外的复制,且不会受到选择的调控。其中有一种观点认为,基因重复使得基因体的复制发生突变之后,并不会对生物体产生负面的影响。这种新基因的突变而产生的结果,可能会增加生物体的适存度,或是新的基因片段功能,产生适应性基因重复(adaptive gene duplications)。
https://zh.wikipedia.org/wiki/%E5%9F%BA%E5%9B%A0%E9%87%8D%E8%A4%87
遗传编程(Genetic Programming)中的结构变换操作(Architecture Altering Operation, AAO)是一系列在遗传编程运行过程中对个体子树结构进行修改的变异算子。它的发明借用了自然界中基因重复和缺失(deletion)的机制。(*它的发明在自动定义函数机制(Automatically Defined Function, ADF)之后,用于解决自动定义函数中子树结构改变较为困难,无法进一步推进进化、以及用户需要提前设置树的拓扑的问题。)
Koza在[1]中认为结构变换操作具有如下的五个特点:
- 可以改变整个程序(个体)的结构
- 可以使得某些子程序(ADF)专门化或者泛化
- 可以自动将目标问题分解为若干个子问题,对这些子问题生成对应的解后重新合并为对于整个目标问题的解
- 可以发现整个搜索空间中的低维子空间,并且在这个子空间中搜索
(*最后两条是指AAO和ADF联用的时候整个遗传编程算法的特点)
自然界中的基因重复和基因缺失
基因重复
基因重复是一种少见而且不可预测的遗传行为,它将复制某一段较长的核苷酸序列然后插入回原来的序列中。
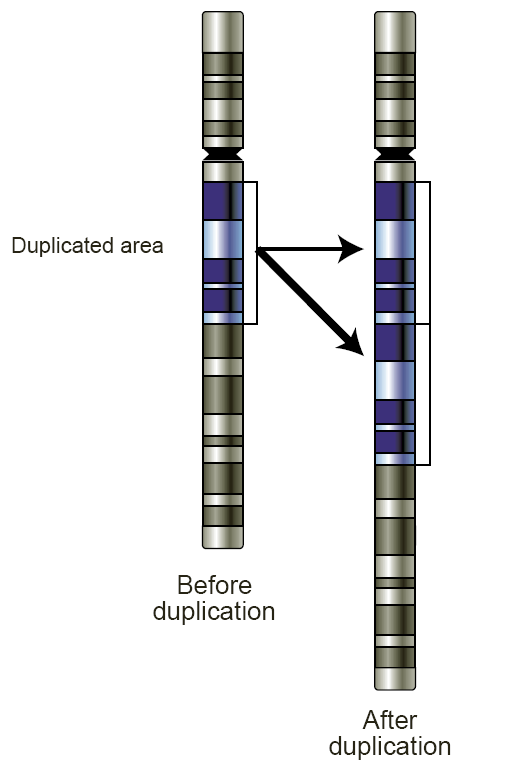
这样做的结果是,这段基因对应的蛋白质会被重复生产。并且随着时间,其他的遗传操作,比如交叉和突变会对这两段或者其中的一段进行作用。
自然选择产生了强大的力量,有利于保持编码制造对生物体的生存和成功表现非常重要的蛋白质的基因。由于复制发生之后,这两段基因会遗传给在这个细胞中全部的后代,也就导致了遗传操作比较容易再次作用在这段基因上。因此,自然选择通常不会或很少会施加压力来维持制造复制品对应产生的某种蛋白质方式。复制品基因可能会积累更多的变化,与原始基因的差异越来越大。当复制品基因开始产生新的蛋白质时,标志着一个新的基因已经产生。如果这个基因对种群的生存有利,自然选择就会作用在该基因上保护这个基因。
相比于达尔文的“优胜劣汰”,大野干强调了自然选择的保护作用:自然选择有效地禁止了影响分子活性位点的变异的延续。
此外,大野干还认为单点交叉和单点突变所引起的基因积累效应不注意推动产生新的基因,进而发生生物进化。(*根本原因是基因的结构比较鲁棒,小范围的对基因的破坏没有什么用)大野干认为,只有通过活性位点上禁止突变的积累,基因位点才能改变其基本特征,成为一个新的基因位点。基因重复提供了摆脱自然选择压力的途径。通过重复,一个基因座就会产生一个多余的拷贝。自然选择往往会忽略这种多余的拷贝,而在被忽略的同时,它又积累了以前被禁止的变化,并重生为一个新的基因位点,具有迄今为止尚不存在的功能。
只要基因组(单倍体组)只包含一个具有重要功能的结构基因位点,自然选择就不会允许这种导致该位点丧失功能的突变永久存在。由于这些突变被禁止伴随基因的增殖过程,因此它们将被定义为禁止突变(forbidden mutation)。[2]
也就是说,基因重复提供了一种保护机制:可以保护原来的基因不受剧烈突变的情况下在该基因的基础上搜索其他的进化可能性。
基因缺失
核苷酸长链中确实了一段可以被翻译和产生功能蛋白质的基因片段。
带有自动定义函数机制的遗传编程存在的问题
自动定义函数机制在遗传编程中的自动定义函数一讲中介绍过,此处不多赘述。
带有自动定义函数机制的遗传编程存在两个问题:
第一是基本上不可能根据先验知识设定到底用多少个ADF才合适,并且ADF中的参数也很难通过先验知识去调整。第二是由于在带有自动定义函数机制的遗传编程中,突变和交叉都是类保护的,也就是说突变和交叉无法改变个体的架构(也就是整体需要多少个函数定义部件和结果生成部件,并且ADF之间的层级关系是如何的)。事实上,如果没有结构变换操作,整个进化过程中种群的结构被限制在了随机生成的初始种群的结构中,无法得到改变。
而结构变换操作提供了一种可以使用进化对个体结构自然而然进行调整的方式。
结构变换操作
结构变换操作一共有三大类:重复(duplication)、缺失(deletion)和创建(creation)。重复和缺失都有对应的生物遗传学基础。
重复
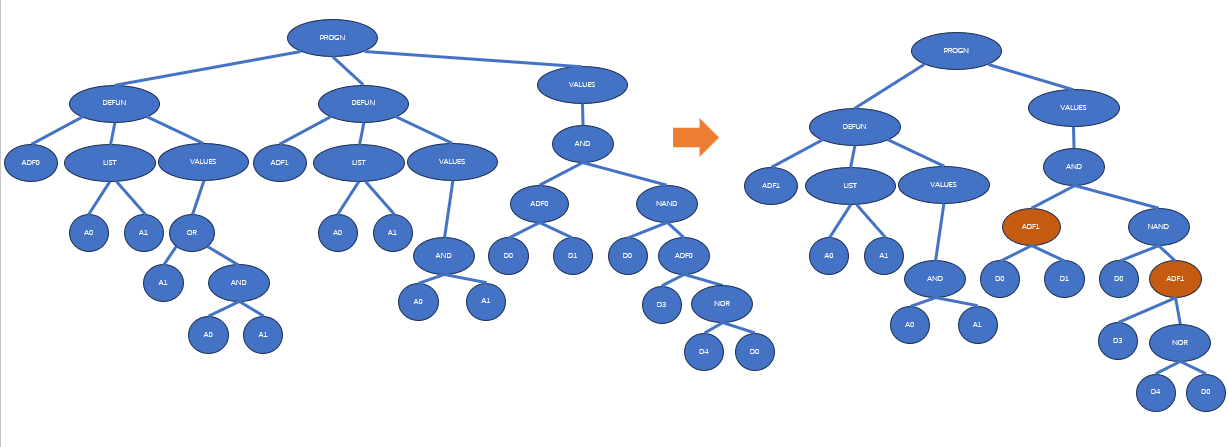
子程序重复
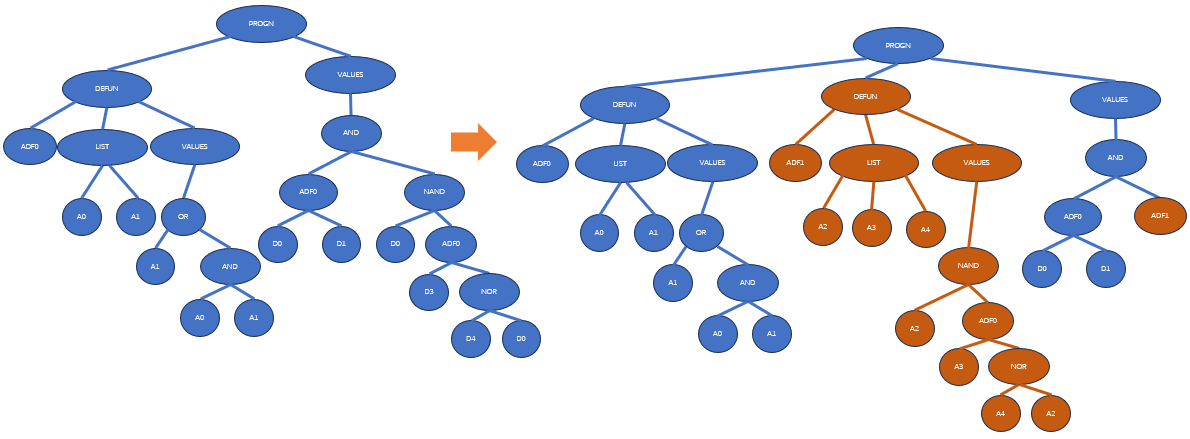
子程序重复(branch duplication)是复制当前一个ADF定义部分的操作,具体如下:
- 选择一个个体参与
- 在这个个体上选择一个函数定义部件(function-defining componet)
- 复制该部件,并且重新命名复制后的函数。复制品具有与原函数完全相同的结构和声明列表(argument list)
- 在该个体中任何需要调用到原函数的地方,随机地选择这个位置仍然调用原函数,或者改为调用复制品函数
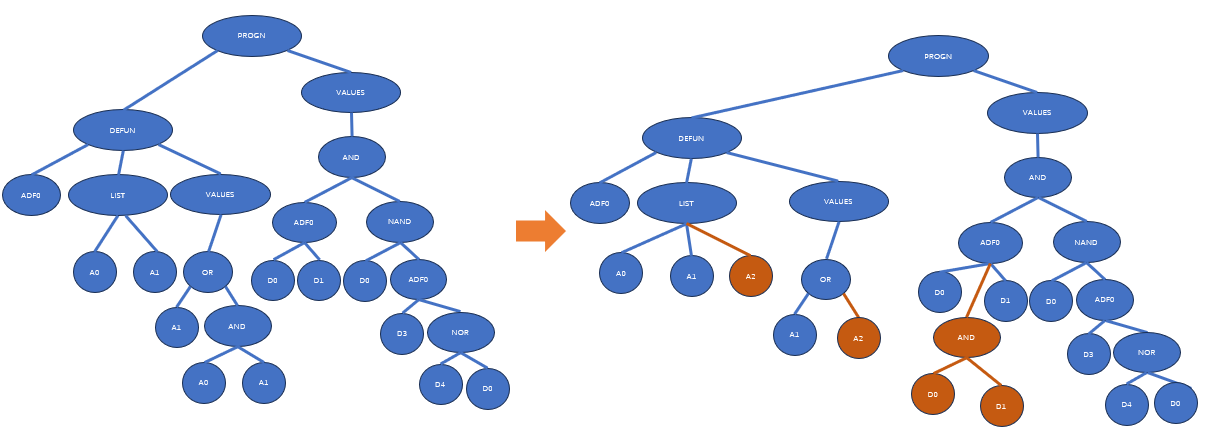
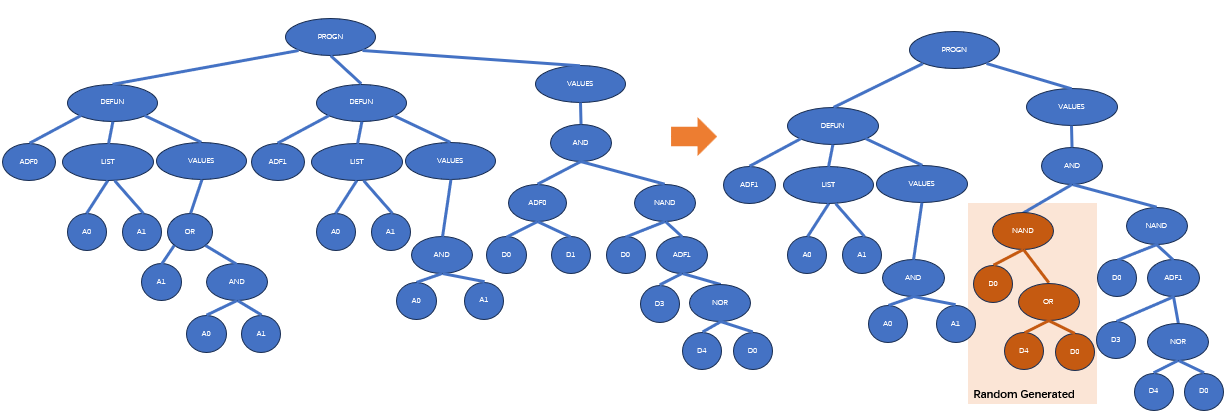
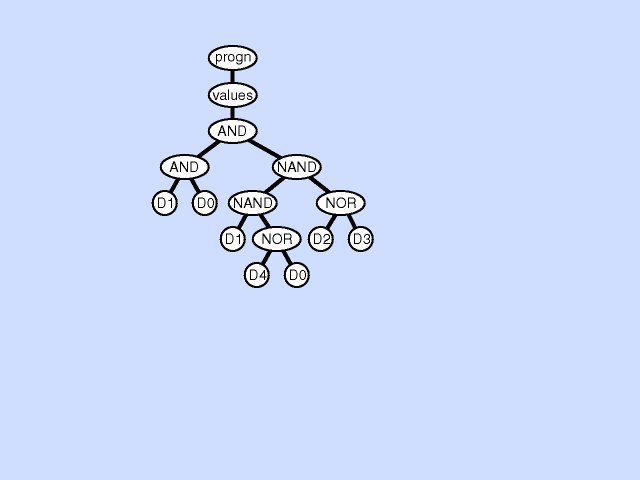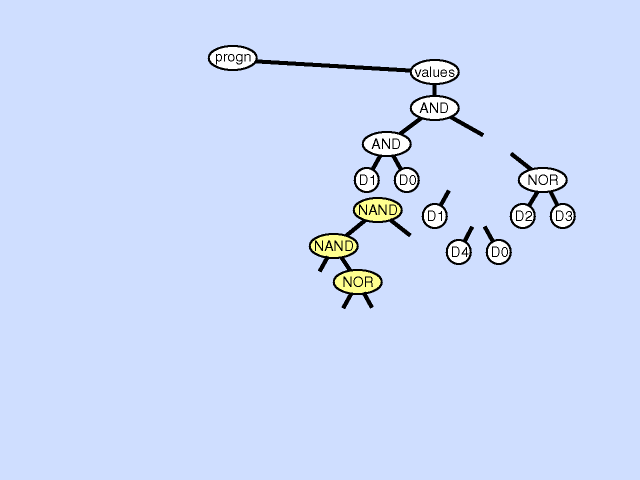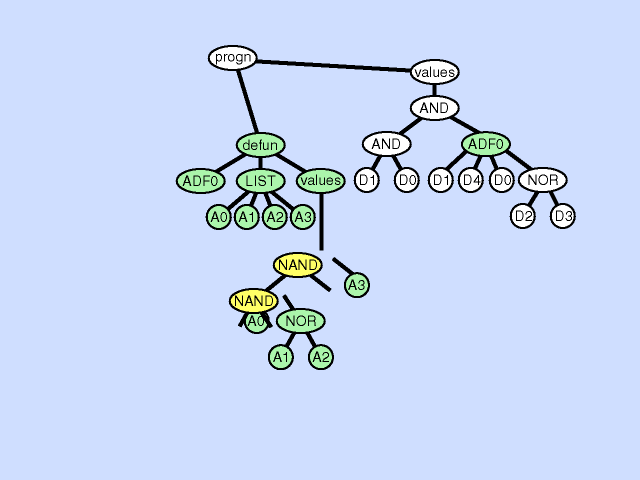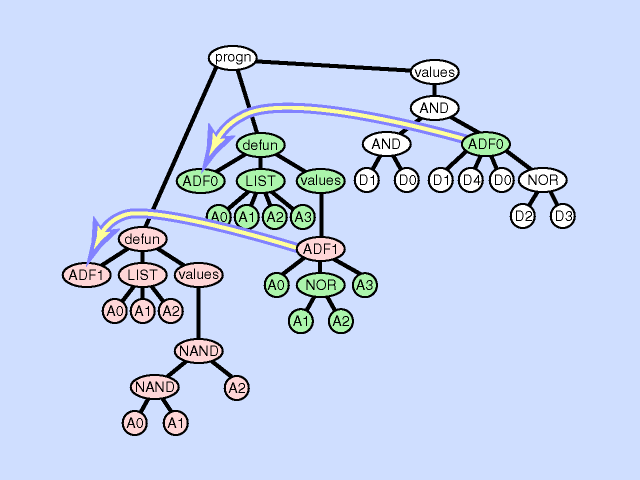
下图展示了一个子程序重复的例子:
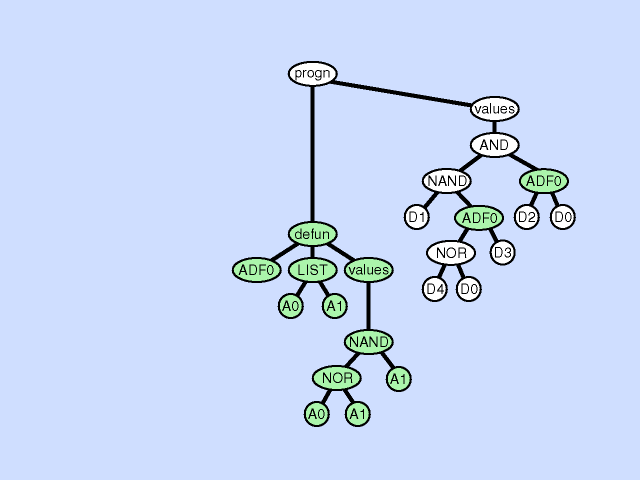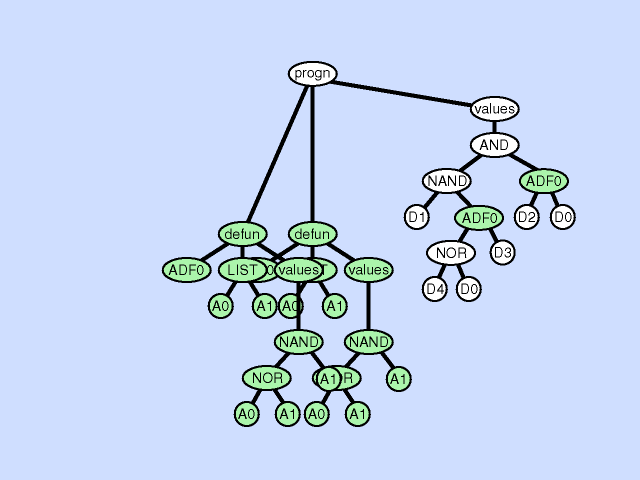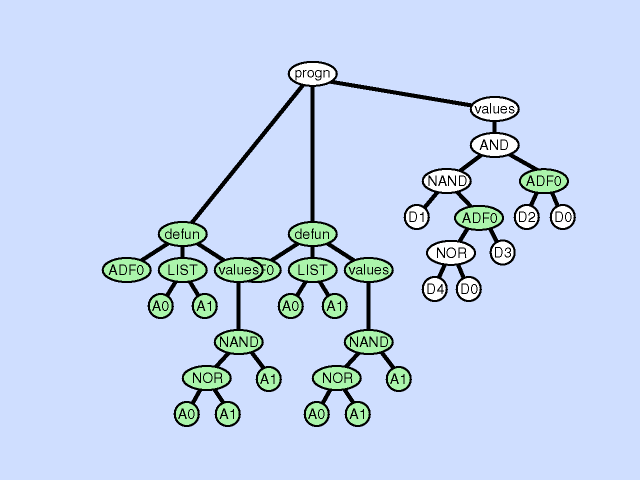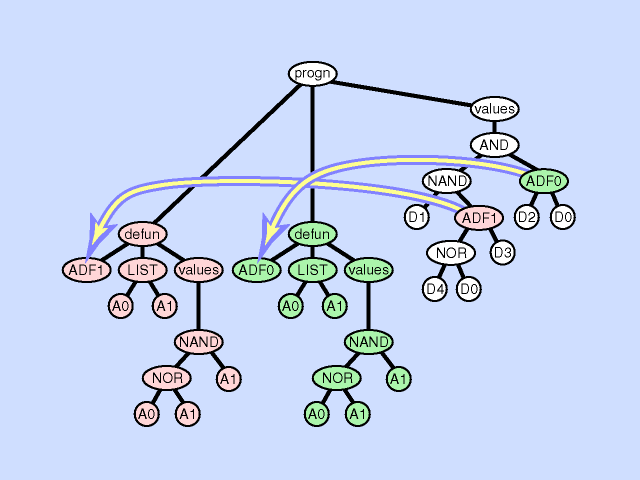
子程序重复可以被解释为一种条件划分。如果把不同的子树分支视作是不同的调用环境的话,子程序重复事实上是把原本不同调用环境的同一处理方式分成了多种处理方式。因此,子程序重复可以看做是一种对某个ADF在不同调用环境下的特化(specialization)。
声明重复
声明重复是一种复制某个ADF中形式参数的方法,具体如下:
- 选择一个个体参与
- 在这个个体上选择一个函数定义部件
- 选择该部件中的一个声明
- 复制这个声明,并且重新命名
- 在这个被选择的函数定义部件中,找到所有需要这个声明的地方,随机选择仍然使用这个声明或者替换为复制后的声明
- 在该个体中任何需要调用到这个函数的地方,找到这个函数,并且复制该调用下一个合适的实体参数(或者子树)作为新的输入接口的输入
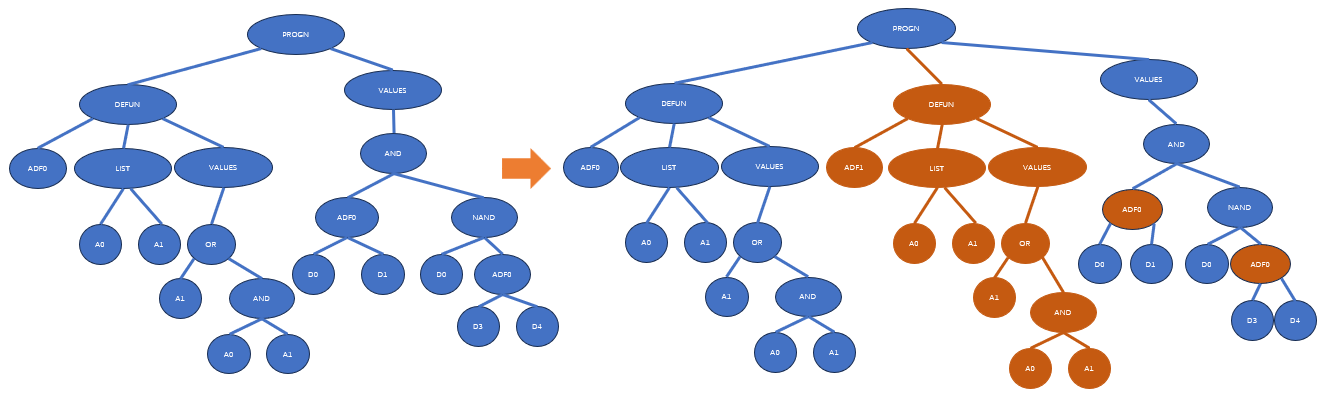
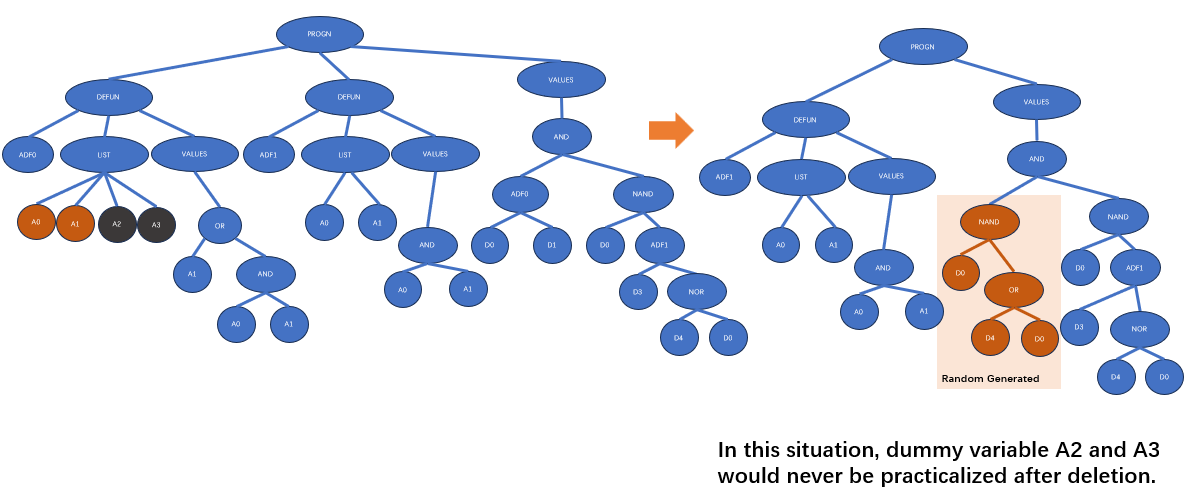
下图展示了一个声明重复的例子:
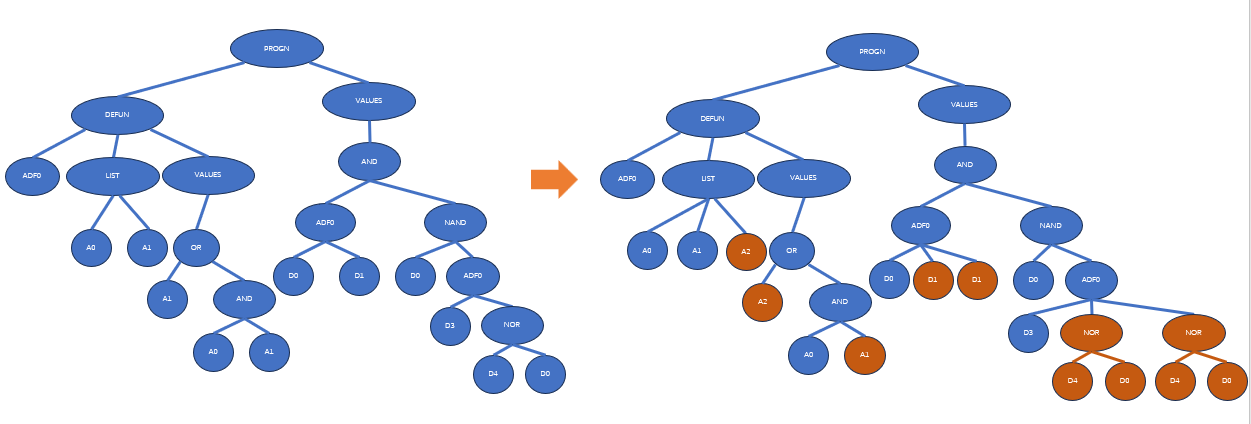
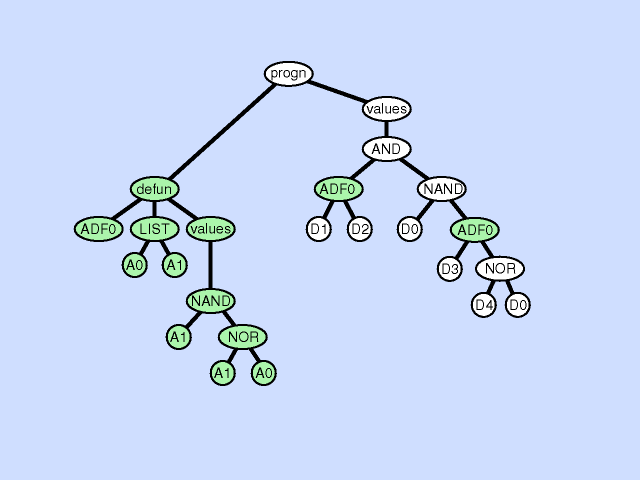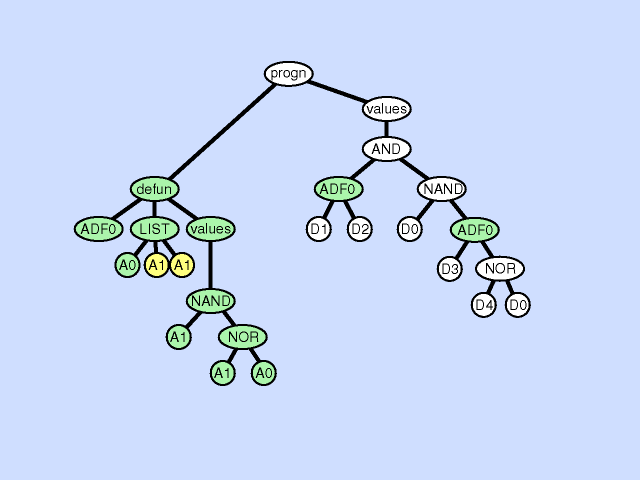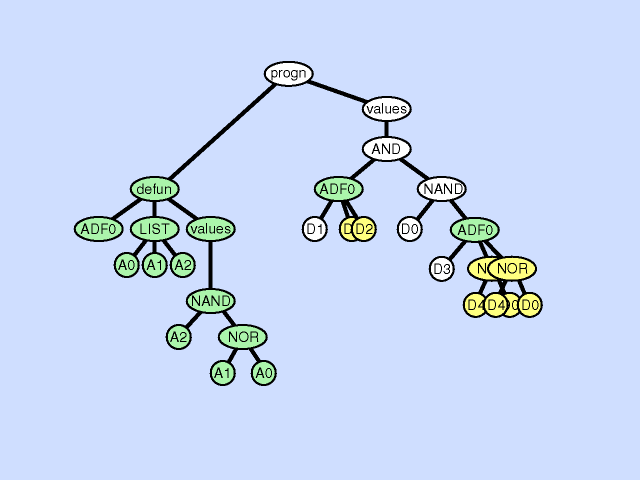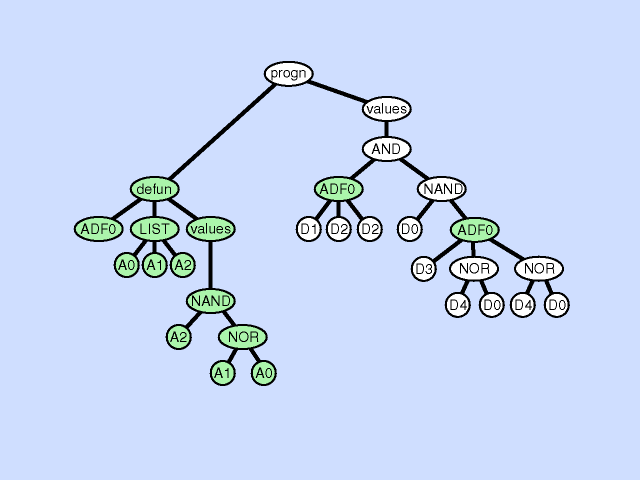
声明重复可以看做是同一个声明在不同情况下的特化。
缺失
和重复一样,缺失也分对子程序的缺失或者是对声明的缺失。但是不论是何种缺失都需要考虑到缺失后在主函数中调用该对象的合法性。
子程序缺失
子程序缺失可以看作是删除了一个ADF,但是由于程序调用的关系,需要考虑更多合法性方面的因素。子程序缺失的具体操作如下:
- 选择一个个体参与
- 在这个个体上选择一个函数定义部件(function-defining componet)
- 删除这个分支
- 在所有调用这个分支的地方,进行一些操作使得该删除不会影响主程序的运行
对于第四个步骤,可以的操作有四种方式:
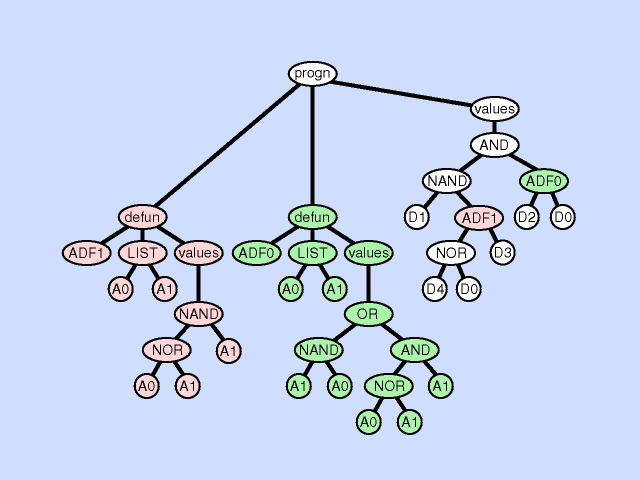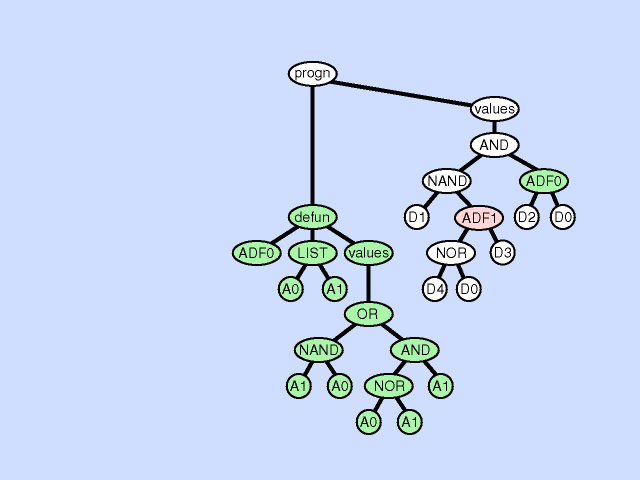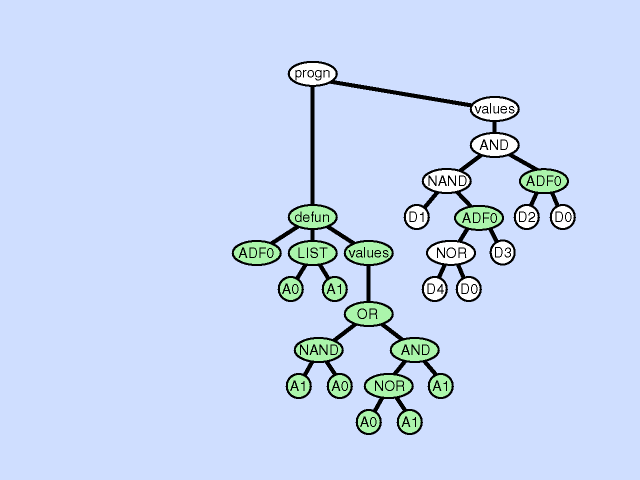
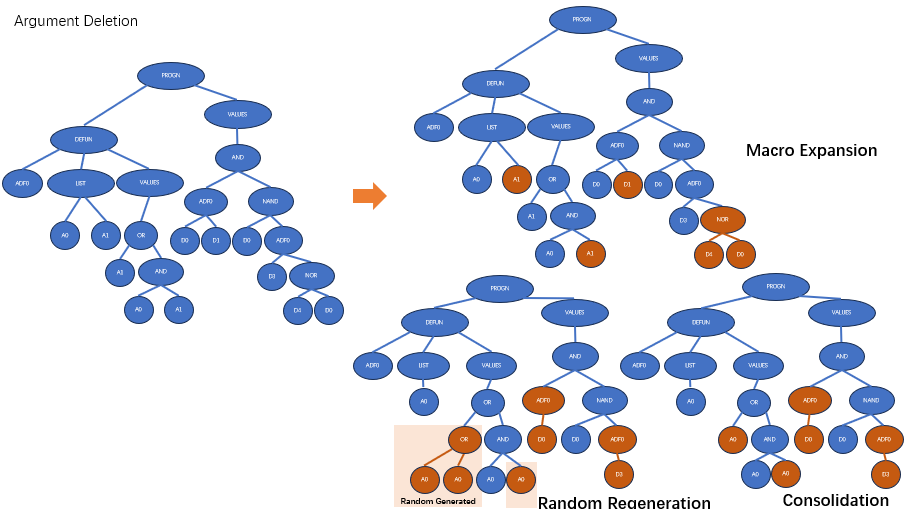
合并(consolidation)
直接该个体的在结果生成部件中用合适的(*同一类的)ADF替换所有调用到这个ADF的地方
这种情况下,与重复正好相反,缺失可以看作是把该情况下特化的ADF被另一个ADF替代,使得用于替代的ADF更加泛化。(原来是不同情况用不同ADF,现在这些情况都是用同一个ADF)
随机重生(random regeneration)
用随机生成的子树代替调用的部分。
在这种情况下,如果删除部分的声明数大于剩下部分的声明数,由于随机生成树的原材料是删除了ADF之后的原材料(基函数集和声明集),因此多出的那部分声明不会被随机生成的树替代,这种情况相当于精简了子参数。
反过来,如果删除部分的声明数小于剩下部分的声明数,随机生成可能并不可取,因为它会给操作带来很大的突变性。在这种情况下,可以简单地放弃随机重生。宏展开(macro expansion)
将原来删除的部分作为一个子树插入到调用的地方。这种情况下,删除只是对遗传操作而言忽略了这部分的进化。它的好处是保护了删除的ADF的结构,但是会导致最终的个体过大,而且也不能改变程序的结构。
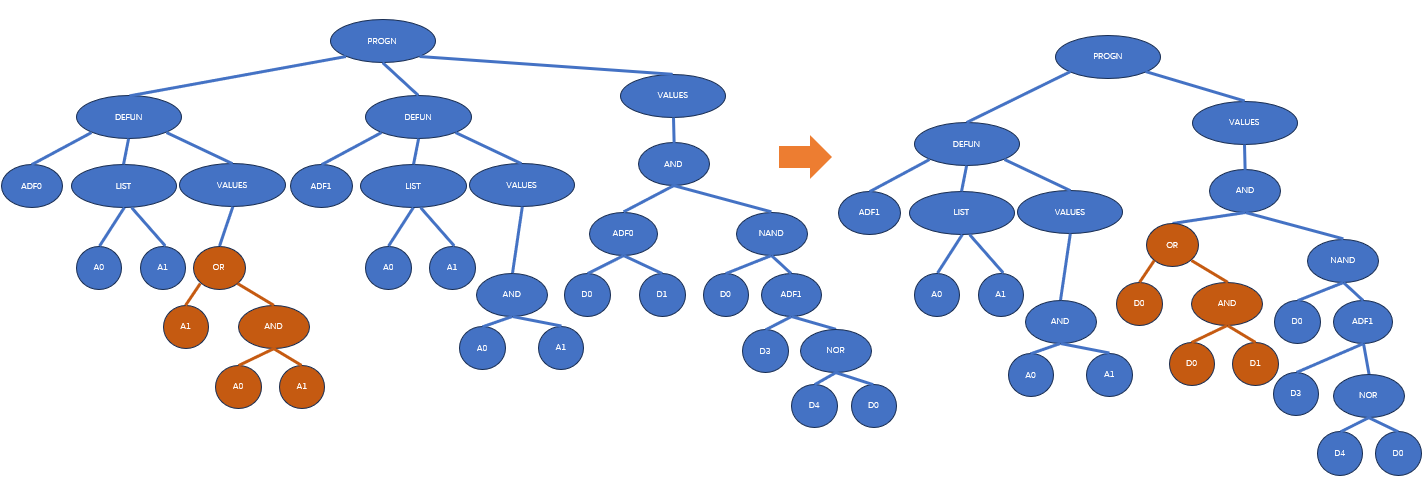
声明缺失
声明缺失(argument deletion)会删除某个ADF中的某个形式参数,具体如下:
- 选择一个个体参与
- 在这个个体上选择一个函数定义部件
- 选择该部件中的一个声明
- 删除这个声明,并且修改声明列表
- 在个体任何地方使用到这个调用的地方删除这个声明对应的实际参数或者子树
- 在这个函数定义部件中使用到被删除声明的地方使用其他方法保证这个部件的合法性。
第六步和子程序缺失一样,同样有合并、随机重生和宏展开三种方法。对于合并,在这个ADF的定义部分选择类似的形式参数替换这个被删除的参数;随机重生既可以随机生成一个子树,也可以随机生成一个变量;宏展开则是在调用时保持使用这个被删除的参数。
两种缺失的作用(除去宏展开)都是将不同情况使用不同的实体改为不同情况下使用同一个实体,因此,缺失可以被视为是一种泛化。
创建
创建是一种打包子树,使其为ADF或者声明的行为。
需要注意的是,在Koza本人的genetic-programming网站上只有子程序创建、没有声明创建。而最早的论文[1]中介绍过声明创建的内容。
子程序创建
子程序创建(branch creation)是将选定好的一个子树打包为ADF的操作,具体如下:
- 选择一个个体参与
- 在这个个体上选择一个函数定义部件或者结果生成部件上的子树
- 在这个子树上选择一个点,这个点将会是即将生成的ADF的最顶端。
- 对这个点下方的子树开始遍历,每遇到一个节点都决定还是否继续向下遍历。
- 遍历结束后,新建一个函数定义部件然后创建一个新的ADF,把这个子树作为一个新的ADF的
VALUES的下方,并检查被遍历到的子树的实体参数,将它们替换为形式参数。
- 将原来子树的位置用现在新的ADF替换。
- 如果原来的子树下方还有要被打包的点,那么重复原来的步骤,把这个点也替换为另一个新的ADF。但是相同声明的名称沿用上一个ADF中重复的部分。
需要注意的是,另外有一种叫做压缩(compression)的遗传操作,也是打包函数,但是压缩打包后的函数与原来的树无关,不再调用替换。
在子程序创建中,打包后的子树是可以进化的,并且任何位置的子树都可以作为新的ADF的模板。
声明创建
声明创建(argument creation)是一种在子树中创建声明的方式,相比于声明复制,这种方式更为通用。声明创建的方式如下:
- 选择一个个体参与
- 在这个个体上选择一个函数定义部件,并且在其上选择一个点
- 增加该部件中的一个声明
- 把之前选择的这个点以下的部分全部换成这个声明
- 在选择的个体中,每次调用这个ADF的时候增加一个子树,这个子树就是之前被替换的部分。