深度卷积生成对抗网络
本文最后更新于 2025年9月1日 上午
深度卷积生成对抗网络
Unsupervised Representation Learning With Deep Convolutional Generative Adversarial Networks, Alec Radford et al, 2016.
介绍
Goodfellow等人在2014年提出的GAN由生成器和鉴别器两部分组成,由于其没有启发式的损失函数/代价函数(cost function)因此在表征学习领域(representation learning)受到欢迎。
表征学习的定义:
Learning representations of the data that make it easier to extract useful information when building classifiers or other predictors.
Representation learning: A review and new perspectives,Yoshua Bengio et al, 2013.
但是GAN存在两个问题:
- 学习过程不稳定,常常导致生成器生成一些无意义的输出。
- 有非常少的文献研究GAN的学习过程到底学习了什么,缺少可视化的学习过程。
本文中提出的深度卷积生成对抗网络(DCGAN,Deep Convolutional Generative Adversarial Network)是一种结合了卷积神经网络(CNN)和生成对抗神经网络(GAN)特点的无监督学习神经网络。其核心思想是将生成式对抗网络GAN中的生成器\(G\)和鉴别器\(D\)中的多层感知机用改进后的卷积神经网络CNN替代,此使得训练过程更加稳定。不仅如此,本文中还对生成器的学习过程进行了可视化,并且还发现了生成器具有的线性运算的性质。
相关工作
非监督的表征学习
非监督表征学习在计算机视觉领域被广泛应用。一些经典的非监督学习方法常常先对数据进行聚类,然后利用聚类结果改进分类。对于图像而言,可以应用层次聚类(hierachical clustering)来学习更强大的图像表征。另一种受欢迎的办法是训练一个自动编码器(auto encoder),提取图像的特征并且将图像进行编码,然后用解码器进行还原。深度信念网络(DBN)也被证明在图像的层次表征学习上有着较好表现。
图像生成
图像生成模型可以分为两大类:基于参数的(parametric)和非参数的(non-parametric)。
其中,非参数的生成模型通常匹配数据集中现有的图像图块(patches)。在纹理分析、超分辨率图像合成和图像修复(in-pating)领域应用广泛。
基于参数的生成模型在纹理分析领域应用较为广泛,然而在生成真实图片领域尚未取得较大成功。在生成图像上,很多采样方法往往会导致生成的图像模糊。另一种方法是使用迭代式前向扩散过程(iterative forward diffusion process)来生成图片,比如GAN。然而GAN生成的图像往往信噪比低而且常常无法解释图像内容。对GAN应用拉普拉斯金字塔(Laplacian pyramid)改进了图像的质量,但是由于噪声的影响,生成图像中的物体看起来是晃动的。
递归网络(recurrent network)和反卷积网络(deconvolutional network)在自然图像生成上取得了一些成功,但是无法将生成器应用于监督学习。
CNN的迭代可视化
长期以来,对卷积神经网络最大的批评就是它是一个黑箱模型,其迭代过程不容易被人类理解。Zeiler等人于2014年使用反卷积和最大激活填充对CNN学习过程中每一个滤波器的作用进行了探究。Mordvintsev等人在网络输入上使用梯度下降方法探究了被激活的滤波器产生的理想图像。
方法论
LAPGAN模型曾经尝试过使用CNN来替代GAN中的感知机网络以提高GAN模型生成图像的质量和模型可靠性,但是没有成功。本文的作者在使用监督学习CNN和GAN融合时也遇到了相似的问题,其解决方法是对融合的CNN模型进行了改进,如此可以使得应对广泛的数据集类型时训练过程更加稳定、并且可以得到更深和更高分辨率的生成模型。
本文中对CNN模型的改进核心有三点,这三点来源于CNN的发展趋势。
步长卷积池化器
使用步长卷积(stride convolution)代替确定性的空间池化函数(例如:最大池化),当步长大于或等于卷积核宽度时,卷积过程中不会对图像进行重复卷积,最终也能够起到缩小上一层图像的效果。
这样的过程称为下采样(downsampling),即采样后的图像大小会缩小,信息密度更高但是采样损失也更大。
通常对于2*2的卷积核,采用0填充,步长等于2的设置也可以达到较好的池化效果。
与传统的池化层不同的是,池化层的卷积核内的权重在训练过程中是不变的。而步长卷积池化的权重通过反向传播不断自我学习和更新,因此这种设置允许网络学习自己的空间下采样。在生成器和判别器中使用这种方法,这样能允许生成器学习自己的空间采样。
消除全连接隐藏层
CNN的发展在卷积特征上消除全连接隐藏层的趋势。全连接层的最经典的例子是全局平均池化层的应用。全局平均池化提高了模型的稳定性,但是降低了收敛速度。
DCGAN中的全连接层存在于生成器的输入层和鉴别器的输出层。
DCGAN的生成器会从噪声分布\(Z\)中采样作为输出,由于这一步只是矩阵乘法,因此也可以看做是全连接层。其后将噪声1维向量重新整合为维度为4的张量,并且将其用做卷积的开始。对于鉴别器,最后一层卷积层采用全连接将张量拉平并且使用Sigmoid函数作为最后的输出。
下图展示了DCGAN训练LSUN数据集时的生成器架构:
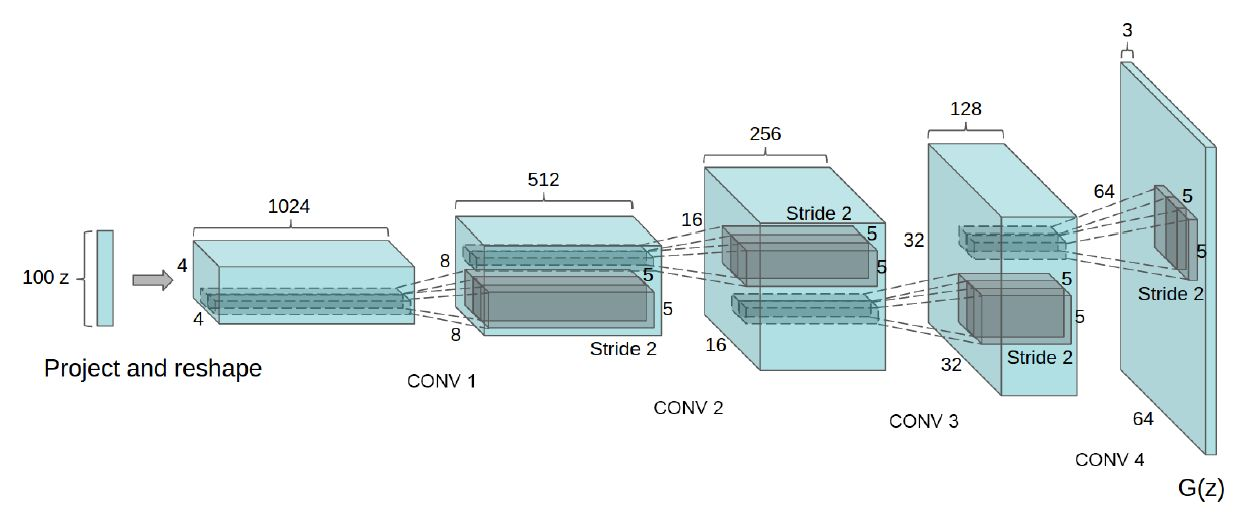
批归一化
就像对网络输入进行归一化一样,在每个小批量训练数据通过网络时,对每个层的输入进行归一化。批归一化(batch normalization)背后所体现的理念是,在处理具有多层的深度神经网络时,仅规范化输入可能还远远不够。当输入值经过一层又一层网络时,它们将被每一层中的可训练参数进行缩放。当参数通过反向传播得到调整时,每一层输入的分布在随后的训练迭代中都容易发生变化,从而影响学习过程的稳定性。这个问题被称为协变量偏移(covariate shift)。批归一化通过按每个小批量的均值和方差缩放每个小批量中的值来解决该问题。
用在GAN中可以防止生成器中的所有样本都被映射到一个点上。
> 批归一化的更多数学推导参见:https://www.cnblogs.com/mogebw/p/15927394.html
ReLU激活函数
在DCGAN中,生成器除了输出层使用tanh函数作为激活函数外,其余层的激活函数都为ReLU函数。生成器的最后一层要输出图像,而图像的像素是有取值范围的([0, 255]),ReLU函数的输出可能会很大,而tanh函数的输出介于[-1, 1]之间,因此输出层选择使用tanh函数作为激活函数。而鉴别器所有层的激活函数都是LeakyReLU。
采用有界的激活函数可以使模型更快收敛并且覆盖训练分布的颜色空间。
实验
参数设置
- 将训练图像数据进行标准化处理,以便tanh函数进行激活,范围为\([-1,1]\)。由于像素值范围为0-255,因此将图像减去均值127.5之后再除以127.5即可。这是唯一的预处理方法。
- 权重随机初始化,数据分布服从以0为中心的正态分布,标准差为0.02。
- 使用Adam优化算法进行优化参数,学习率为0.0002而不是0.001。
- Adam优化算法的动量系数\(β_1=0.5\), \(β_1=0.9\)会导致训练振荡与不稳定。
- LeakyReLU的斜率为0.2,batch_size = 128。
- 采用小批量随机梯度下降进行最优化。
LSUN数据集的训练
在LSUN卧室数据集中训练了一个模型,该数据集包含300多万个训练示例。最近的分析表明,模型的学习速度与其泛化性能之间存在着直接联系。下图为训练了一轮之后的模型生成的样本,用于模拟在线学习。训练采用了较小的学习率和小批量随机梯度下降,目前的文献中没有证据表明采用小批量随机梯度下降和较低的训练速度具有记忆能力。以此证明模型并没有通过简单的过拟合/记忆训练示例来生成高质量的样本。
(注:在实验中未对图像进行数据增强处理)

下面展示了训练五轮之后的生成样本:

床单等物品上的噪声纹理暗示训练欠拟合。
训练过程的可视化
多方面的学习了解通常可以告诉我们关于记忆的迹象(如果是尖锐的转换)和在空间中是分层坍塌的形式。如果在潜空间会导致图像生成(例如添加图像和移除图像)的语义变化,可以推论出,模型已经学会了与之相关的表示。

最上面一行的图片显示了\(Z\)空间中的学习具有平滑的转变,空间中的每一张图都看起来像一间卧室。第六行的图片显示了一间没有窗子的图片是如何转变最终生成一张具有巨大窗子的图片。第十行的图片显示了一个电视是如何渐渐转变为一个窗户的。
模型特征的可视化
过去的研究中已经证明了监督学习的CNN具有强大的提取特征的能力,事实上DCGAN也具有这样强大的提取特征的能力。下图展示了以LSUN训练集训练好的模型构建的滤波器对图像的特征提取结果,将其与随机生成的滤波器提取特征结果对比。

生成模型表达式的操作——去除特定的对象
除了判别器学习到的表示,这里也有一个问题,生成器学习到的表示是什么。
样本的质量展示出,对于主要场景成分,例如床、窗户、灯具、门和混杂的家具,生成器学习特定的目标表示。为了探索这些表现所使用的形式,作者进行了一个实验,尝试从生成器中完全去除窗户。
在150个样本上,手工绘制了52个窗口边框。在第二高卷积特征上,通过给定标准让绘制边界框内的激活是正的,来自同一个图像的随机样本是负的,用逻辑回归来拟合预测一个特征激活是否在窗口上。使用这个简单的模型,将所有的特征映射(权重都大于0,总共200),都从空间位置中移除出去。接着,随机生成的新样本是在有特征映射移除和没有特征映射移除的情况下生成的。 
上中显示了有窗户移除和没有窗户移除的生成图像,有趣的是,网络通常会忘记在卧室内画窗户,而用其他物品替代。
从这个实验可以看出,生成器确实学到了“窗子”这样一个特征。虽然视觉质量下降了,但整体场景构成保持不变,这表明生成器在将场景表示与对象表示分离方面做得很好。可以通过扩展实验从图像中删除其他对象并修改生成器绘制的对象。
生成器的向量运算性质
本文中还探究了生成器所具有的的向量运算性质。其中发现在\(Z\)空间中,如果对图像对应的\(Z\)向量进行排除或添加,其生成的图片也会具有相应的操作。例如进行如下操作: \[Z向量“smiling woman”-Z向量“Netural woman”+Z向量“Netural man”\] 其对应的图像中的“woman”特征也被相应排除,添加上特征“man”,从而生成一张“smiling man”的图片。如下图所示:
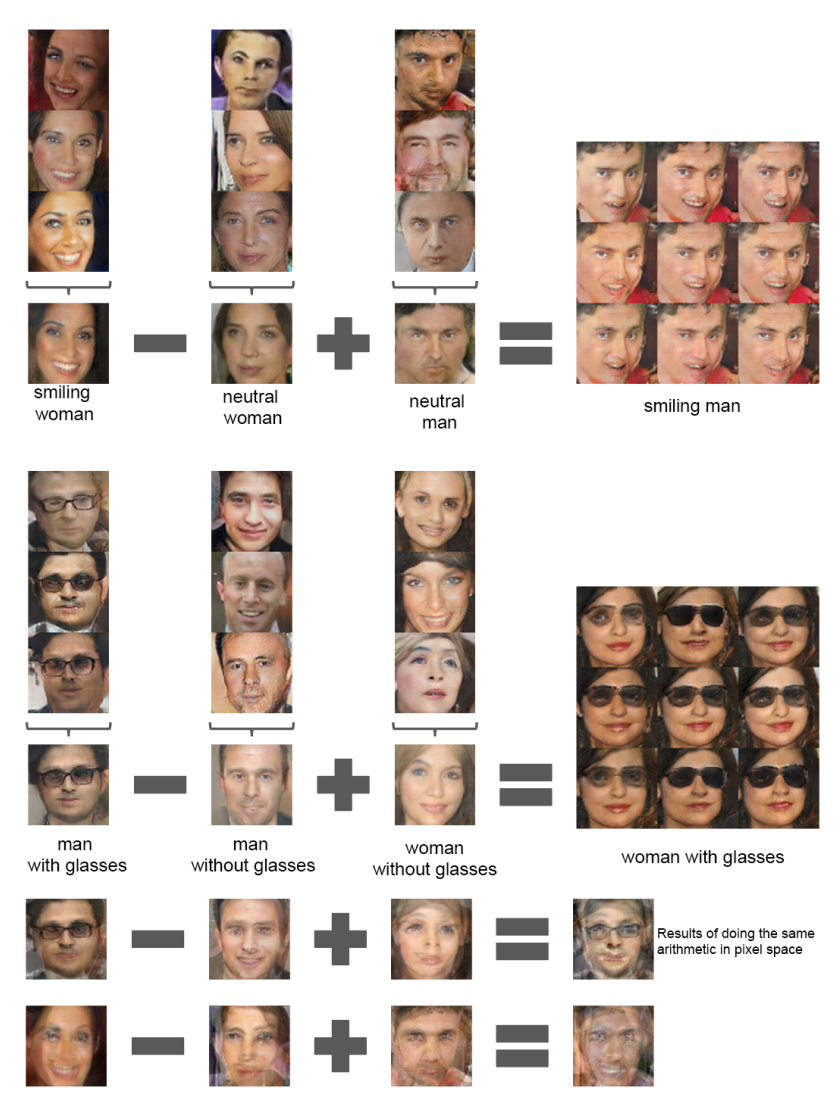
也就是说,生成器在\(Z\)空间中具有线性运算的特性。这是第一次在纯粹的无监督网络模型中发现这样的性质。
同时也可以尝试通过对向量的旋转操作,旋转每个\(Z\)空间中的向量来改变生成图片中的人脸朝向,如下图所示:
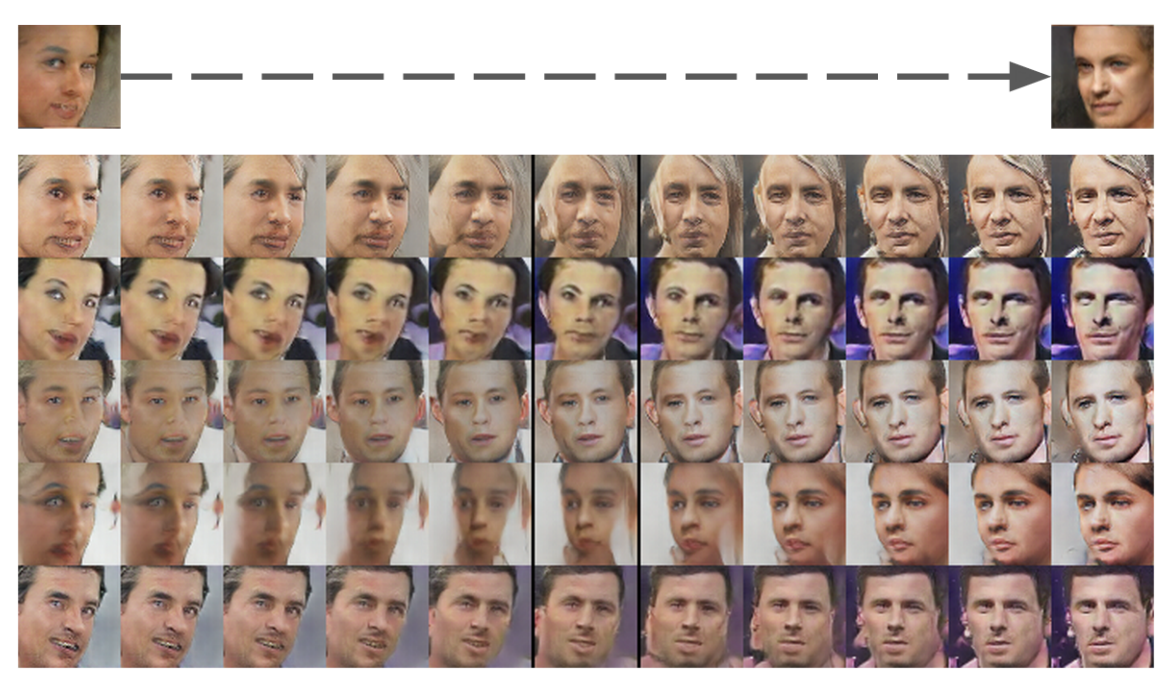
验证
本文中用Imagenet-1k数据集训练的好的鉴别器中的特征应用最大池化生成4×4的矩阵,然后被展平为一个维度为28672的向量,应用到一个正规化的线性L2-SVM分类器上。该分类器对于数据集CIFAN-10图片的分类器准确率达到了82.8%。
下表展示了几种算法的分类准确率:

可以发现,DCGAN的性能略弱于范例卷积神经网络(Exemplar CNN)。在未来,还可以对鉴别器的表示有所调整。由于DCGAN并没有训练CIFAN-10中的图片,在这个实验中其学习到的特征表现出了良好的鲁棒性。
对于标签非常多的数据集,例如具有1000个标签的SVHN数据集,采用如上描述的同样的方法构造L2-SVM分类器,得到其具有22.48%的误差。
下表展示了多种算法的分类误差:
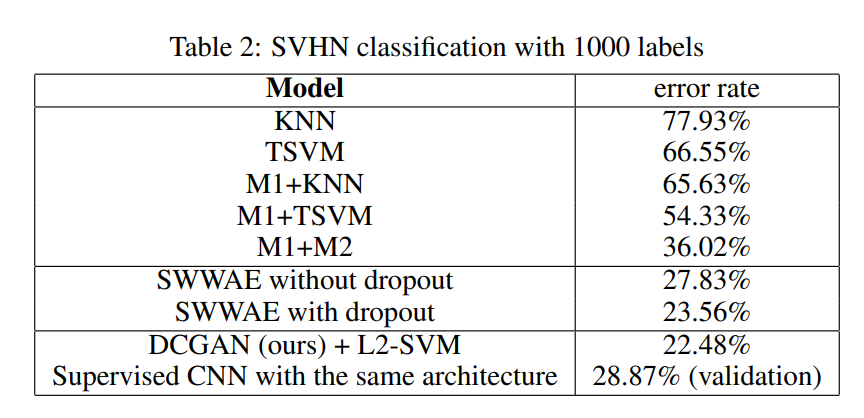
值得注意的是,相比于同样架构的监督学习CNN,DCGAN+L2-SVM的误差更小。表明了DCGAN优秀的特征提取能力。