01. 绪论
本文最后更新于 2025年6月4日 晚上
这是对《Genetic Programming IV: Routine Human-Competitive Machine Intelligence》的笔记,本页对应第一章: Chapter 1: Introduction.
这一章讲述了对机器学习最根本三个性质的定义以及进化计算在这三个性质上的体现。以及本书其他核心观点的解读。
原书的免费公开版本在作者Koza本人的Research gate主页上:https://www.researchgate.net/publication/243776894_Genetic_Programming_IV_Routine_Human-Competitive_Machine_Intelligence
这本书也可以在Springer 购买电子版: https://link.springer.com/book/10.1007/b137549
或者在亚马逊英国购买纸质版: https://www.amazon.co.uk/Genetic-Programming-IV-Human-Competitive-Intelligence/dp/0387250670
绪论
遗传编程(Genetic Programming)是一种系统的用于让计算机自动生成解决方案的算法。遗传编程开始于对于需求的高阶描述,然后会自动创建计算机程序来达成这一需求。
本书对遗传编程的理解一共有四个观点,其中最重要的一个观点是: 遗传编程现在是一种例程化的、高回报的、可比拟人类的机器智能。(Genetic Programming now routinely delivers high-return human-competitive machine intelligence.)
第二个观点是:遗传编程是一种自动发明的机器。(Genetic Programming is an automated invention machine.)。本书的作者认为,检验一个事物是否为新发明的标准是是否可专利(patentability)。可专利的先决条件是具有创新性和创造力。如果只是对现有的知识进行变换,那算不上是发明。一个新的想法只有经过某些“非逻辑性”的步骤(illogical step)才能将其与从现有知识中推断得到的想法区分开。遗传编程并不会按照过去人类积累的知识进行创新。因此,按照上述理论,由于没有建立在既有知识之上,遗传编程对问题给出的解答可以称之为发明。
也就是说,遗传编程对先验知识的依赖非常小。
本书的第三个观点是:遗传编程可以为特定问题自动化地生成参数化拓扑结构表示的通解。(Genetic Programming can automatically created a general solution to a problem in the form of a parameterized topology.)。也就是说,遗传编程产生的解是用图形结构的方式来表达的。
本书的第四个观点是:与计算机时间消耗的五个大约数量级的增长同步,遗传编程也取得了质的飞跃。(Genetic Programming has delivered a progression of qualitatively more substantial results in synchrony with five approximately order-of-magnitude increasees in the expenditure of computer time.)换言之,遗传编程享受了来自摩尔定律(Moore’s Law)的红利。
总的来说,遗传编程不同于现存(*2003年本书写成时)的其他机器学习算法的点在于:遗传编程既可以复现过去大量的专利、也可以创作出新的可被专利化的结果,并且具有独特的以“出生”和“死亡”筛选解决问题的方案的机制。最重要的是,它是一种例程化的、高回报的、可比拟人类的机器智能。
一种例程化的、高回报的、可比拟人类的机器智能
这一小节,作者将会对上述标题中的关键词做出详细的定义。
可比拟人类的
Arthur Samuel曾经在他的演讲中提到过: “人类是需要动用智慧来展示一个复杂问题的。……的目的是为了让机器具有展示问题的行为。”
> “[T]he aim [is]…to get machines to exhibit behavior, which if done by humans, would be assumed to involve the use of intelligence.”
这样的问题在机器学习中被称为“玩具问题”(toy problem),指在科学上没有立即解决的重要性,不过可以作为玩具与其他人说明更复杂问题的特征。Samuel的发言反映了 20 世纪 50 年代人工智能和机器学习领域先驱们所阐述的共同目标。事实上,让机器产生与人类类似的结果,正是人工智能和机器学习领域存在的理由。为了更加具体的描述这一目标,本书的作者列举了八条衡量一个机器学习算法是否具备“可比拟人类”(human-competitive)的性质的标准。满足这八条标准中的一条或者几条的机器学习算法可以称为具有“可比拟人类”的性质。
| 序号 | 说明 |
|---|---|
| A | 该成果过去曾作为发明获得专利,是对已获专利发明的改进,或在今天有资格作为可获得专利的新发明。 |
| B | 该成果等同于或优于在同行评审的科学杂志上发表时被接受为新科学成果的成果。 |
| C | 该成果等同于或优于由国际公认的科学专家小组维护的数据库或成果档案。 |
| D | 该成果本身可作为新的科学成果发表——与该成果是机械创造的事实无关。 |
| E | 该成果等同于或优于人类对一个长期存在的问题所创造的最新解决方案。人类对该问题所创造的解决方案需要是越来越好的。 |
| F | 该成果等同于或优于在首次发现时被认为是该领域成就的成果。 |
| G | 该成果解决了其领域内无可争议的难题。 |
| H | 该成果在有人类参赛者参加的规范竞赛中独占鳌头或获胜(以人类选手或人类编写的计算机程序)。 |
高回报的
本书中定义了一个概念,称为AI比(artificial-to-intelligence ratio),表示一个智能方法中先验知识的参与程度:
\[\begin{aligned} \text{A-I Ratio} &= \frac{Artificial \text{(refer to a method designed by human-beings)}}{Intelligence \text{(from human-beings)}}\\ &=\frac{\text{人工设计的方法自动运行时产生的智能}}{\text{人类提供给该方法的专业智能}} \end{aligned} \] AI比越高,代表机器智能在运行时所需要的人类参与度更小。换句话而言,对于AI比高的机器算法,人类只需要投入非常少的精力和先验知识,就可以让机器自动产生非常高的智能来解决问题,这就是所谓的“高回报的”(High-Return)。作者在这里举了深蓝和一个由Chinook等人设计的棋谱机器人的例子来说明高回报。简而言之,人类在机器算法运行过程中的参与度直接与回报率(如果把人类的投入视为成本,解的有效程度视为收入的话),或者说AI比相关,人类在运行过程中的参与度越高,得到的问题的解的回报率越低。
例程化的
通用性(generality)是对一个自动解决问题机器是否具有例程(routine)的先决条件。例程是指,在较少的人力需求下,机器智能可以处理来自本领域的新问题和来自其他领域的新问题。
简单来说例程化就是机器学习方法的可迁移性。包括对同一领域不同问题和不同领域的新问题两方面的可迁移性。
如果解决问题的方法在新问题上的应用需要人为的修改运行步骤,那么这不能成为例程化的。
机器智能
在1950年代,如果机器表现的行为与人类需要智能时表现的行为一致,那么称这样的机器是人工智能/机器智能。但是如今AI和机器学习的智能变得狭窄,指运用知识和逻辑自动解决问题的方式。如果我们倒回1950年,根据这样的对人工智能或者说机器智能的定义,图灵提出了三种实现类人机器智能的方法:
逻辑驱动的搜索(logic-driven search)
图灵自己在1930年代通过设计逻辑电路实现了计算机的基础。
而后神经网络的感知机和逻辑回归都可以算作此类。
文化搜索(cultral search)
简单来说就是综合迄今为止人类的全部知识来解决某一特定问题。这一理论是专家系统(expert system)的基础。
近年来提出的大模型等等可以视为属于这一范畴。
基因搜索(genetical or evolutionary search)
这一理论是根据图灵在1948年发表的论文中出现的:
> “There is the genetical or evolutionary search by which a combination of genes is looked for, the creterion being the survival value.”这是整个进化计算研究领域的开始。可以发现最早图灵对基因搜索的理解只包含了搜索和评估两个步骤,而后在1948年和1950年图灵的论文中又陆续加入了选择压力(现在称之为适应度和适应度衡量)、突变等等概念。
遗传编程在上述定义的体现
可比拟人类的
本书中直接列出了一个含有36个使用遗传编程进行发明创造的例子的表格来说明遗传编程是可比拟人类的。简单来说就是遗传编程的给出的结果是可以被专利化或者发表的。
高回报的
对AI比的进一步理解和诠释是,“人类提供给该方法的专业智能”可以看做是智能系统的输入,而“人工设计的方法自动运行时产生的智能”可以看做是智能系统的输出。对于遗传编程而言,这两者可以很明确的被划分“准备步骤”(preparatory steps,对应‘人类提供给该方法的专业智能’)和“执行步骤”(executional steps,对应“人工设计的方法自动运行时产生的智能”)。准备步骤包括了人类需要对算法进行的输入和定义(*也就是机器学习中常说的超参数/控制参数),执行步骤则是算法具体的运行流程。在本小节中,作者将重点阐释遗传编程所需要的准备步骤。
遗传编程所需要的准备步骤包括:
- 端点集合(set of terminals),也就是运算数(operands),包括了独立变量、零参数函数(计算机程序中不需要任何输入的函数)、随机常数等等。
- 初级函数集合(set of primitive functions),也就是运算符(operator)。
- 适应度的衡量(fitness measure)。
- 控制程序运行的参数。
- 终止条件(termination criterion)和指定作为程序最终结果的方法(method for designating the result of the run)。
综合起来,整个遗传编程可以看作是如下图所示的一个智能系统:
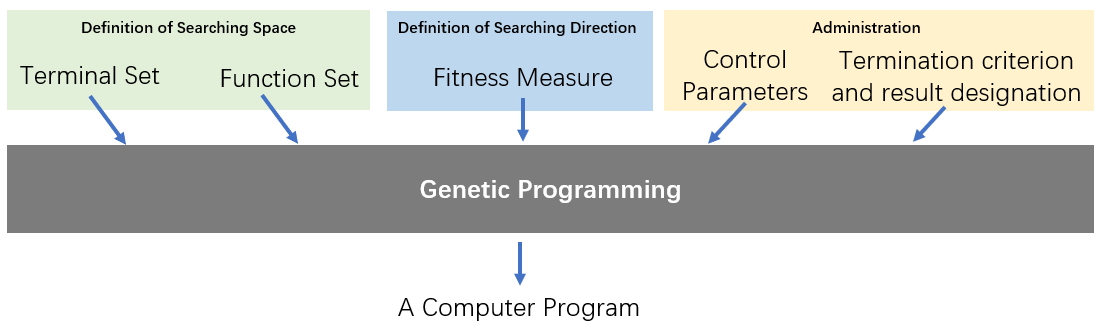
这个系统中五个准备步骤作为系统的输入,系统的输出是可以解决目标问题的一个计算机程序。
搜索空间定义
遗传算法需要体检给出问题解决方式的基本要件。端点集合和搜索函数集合就规定了可能的目标解的基本组成部分,定义了搜索空间(searching space),也就是存在可能可以解决目标问题解的一个空间。(*关于搜索空间更详细的定义请参考genetic algorithm tutorial)。这是一种最低限度的问题理解的描述,其他的机器学习算法也需要类似的对问题的理解(但有可能不是最低限度的理解)。
题外话:GEP中的搜索空间
相比于遗传算法和遗传编程,基因表达式编程算法的个体除了有基因型之外,还有表现型,一般认为基因型表示的是问题空间,而表现型对应的是解的空间,搜索在解的空间上进行,这样的筛选过程并不会破坏原来的问题空间。并且问题空间可以使用通用的设计原则,然后设计额外的映射规则将通用原则映射到特定问题的搜索空间上,形成解的空间。这是GEP比GA和GP高明的地方。
搜索方向的定义
第三步,确定适应度的衡量规范则是遗传编程中对遗传编程搜索方向(searching direction)的定义。由于遗传编程中的每个个体都是代表了一种问题的可能解,因此有必要确立一种方式评价每个个体的好坏,让好的个体可以继续进行下一次的进化,这就是适应度衡量的初衷。
简单来说,适应度衡量是一种对解决问题需求的高级描述,它描述算法的使用者希望解能够达到的最终效果。此处作者举了一大堆例子说明什么是对期望的高级描述。
需要注意的是,针对现实世界问题的需求往往都不是只有一个的,因此搜索的方向和目标可能不止一个,并且可能存在冲突,需要采取某些方式对这些搜索目标进行综合和权衡。(*此处作者给出的解决方案是对多个目标进行线性组合,然后转换为单目标问题解决,但是在后期许多针对多目标优化的算法都采用了帕累托优化的方法,这种方法相比于线性组合转换为单目标优化更加无偏。)
题外话:多目标优化
多目标优化的引入是将原来单目标中的搜索空间加以限制(比如要在保证产率最大化的同时二氧化碳排放量达到最小),在单目标优化中多个目标的剩下的所有目标可以视为是对某一个目标的的限制条件(比如将产率最大化作为二氧化碳排放量最小的限制条件),或者说单目标优化本身的优化函数就建立在其他目标所组成的限制条件下(比如说在产率最大化的时候收集二氧化碳排放量的数据建模,此时的数学模型从某种程度上是隐含了产率最大化这一限制)。
限制对于单目标优化而言则是先验知识的加入,而多目标优化的引入减少了对于经验知识的依赖。换言之,多目标优化是把对经验知识的依赖转换为了更广域和低效(理论上)的搜索代价。
运行管理
第四个和第五个准备步骤都与遗传编程算法执行过程中的运行管理相关。最主要的控制参数是种群的大小和运行的代数。由于计算量的问题,遗传编程中的种群大小设置并不是按照数学分析得出的,而是根据期望的程序运行时间所可以支撑的最大代数反推出的种群大小,因为种群中的个体数量越多,每一代所需要评估和执行遗传操作的个体就越多,计算量和计算时间就会越大。(*我自己对GA的实验是,这样的放大是指数级的。)
可以想象,如果种群大小趋近于无穷,那么本质上遗传编程将遵循“test-pass”原则在一代中就会找到最优解。
对其他的超参数(例如交叉和突变的概率等等你)的设置也基本上使其符合进化计算研究领域长期积累的经验设置就可以了。
另外,不要试图通过找最优超参数来妄图取得对包括遗传编程在内的一系列进化计算算法的重大改进。
这是因为根据理论,在时间尺度无限大的的范围内,在搜索空间的定义非常好(指的是均匀且凸显优化目标和变量关系)的前提下,根据schema theory,不管采取什么样的超参数设置,GA/GP/GEP总是能够找到全局的最优解。
比如根据GA的Schema theory取最极端的\(p_m=1\)和\(p_c=1\):
\(p_m=1\)时,\(P(H,t)≥0\),这是随机搜索,但是只要搜索的持续时间足够长总能“摸”到最优解。
\(p_c=1\)时,\(P(H,t)≥P(H,0)\frac{f(H,0)}{\overline{f}}(\frac{2L-ΔH-2}{L-1})\)(忽略突变以简化推导),对于定义距长到\(ΔH=L-1\)的种群(个体),有\(P(H,t)≥[P(H,0)\frac{f(H,0)}{\overline{f}}]^t\),对于定义距短到0的种群,有\(P(H,t)≥2^t[P(H,0)\frac{f(H,0)}{\overline{f}}]^t\),两种情况下只要种群的适应度大于平均是适应度,那么种群在\(t\)代存活的概率就越大。
例程
简单来说,如果要将遗传编程迁移到新的问题上,所需要改变的工作都是准备阶段的步骤,算法的运行过程并未做任何改变。
- 对于同一领域的不同问题,遗传编程需要更改的只是适应度的评估方法。
- 对于不同领域的新问题,遗传编程需要更改对搜索空间的定义和对适应度的评估方法。
机器智能
这个部分可以用本书的原话说明: > As will be seen thourghout this book, genetic programming dose indeed succeed in getting computers to automatically solve problems from a high-level statement of what need to be done.
一种自动发明机器
创新是不确定和非逻辑的
在这一章节的开头,作者花了相当长的篇幅说明了负反馈放大器的诞生过程,这一个发明小故事的完整翻译在:技术杂谈-负反馈放大器的发明故事
简单来说,作者想要通过这个故事表明,人类进行发明创造的过程中总是会有“灵光一闪”的时刻,而这恰恰说明了发明创造过程中的非逻辑性(illogical)和不确定性(none-deterministic)。
在机器学习领域,“问题解决机器应当是具有逻辑性和确定性的”这种未经严格验证的观点领导了整个研究领域相当长的时间(*特指做传统神经网络的那一帮人),以至于后来所有的传统智能算法都按照这个指导思想进行设计。
但是进化和发明并不是逻辑的,也不是确定的。所以传统的智能算法无法创造任何事物。
在进化领域,以逻辑为基础的智能无法解决创造个体和进化这两个生物过程,因为这两个生物过程都不遵循任何逻辑,也没有任何确定性。(*此处Koza还暗喷了Holland的遗传算法)。不确定性在进化上的体现是进化会生成某些与预期不符合甚至是冲突的解决方案,这些解决方案会被进化过程主动的保留和维护(maintainace)。
从哲学的角度来看,我们一般认为社会达尔文主义者强调的是“优胜劣汰”法则。有意思的是此处强调的则是社会达尔文主义的另一个方面,“物种”,或者说“人”的多样性有助于社会的进步和发展。也就是说异质化的社会会为社会的发展提供更多的可能性和发展条件。
上面这一大段话作者想要强调的是物种多样性对于遗传编程的重要性,即当前种群中那些适应度较低的个体仍然对进化起着重要的作用。此处这么说是因为随着进化计算的研究,后人发现对进化真正起到决定性作用的并不是个体的适应度,而是个体中那些可以用来描述整个问题优秀解的基因片段。某些含有这样基因片段的个体可能会在当前表现出低的适应度,但是随着遗传操作的进行,这些优秀的基因会逐渐暴露出来,从而使个体表现为高适应度。
根据目前我的理解,可以将上述表述描述为下图:
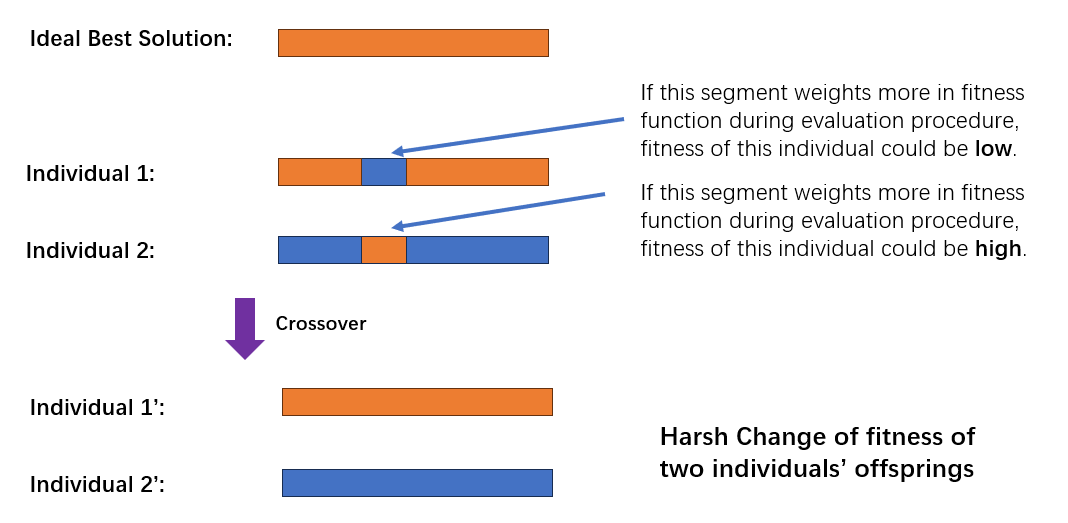
由于遗传编程中遗传操作对于个体的破坏性过大,在遗传编程中强调多样性不失为一种取巧的改进措施。
遗传编程中没有过度的经验主义
另一点需要强调的是,由于遗传编程是一种高AI比算法,因此遗传编程中给出的解中人类的先验知识提供的智能占比非常少,这就使得遗传编程可以提供完全不同于人类的新兴解决方案。
在准备阶段也不需要考虑这些设置是否符合人类的直觉,也不需要过度的人类经验,因此遗传编程所能给出的结果要远超人类科学家的想象。
预训练和迁移学习是先验吗?
- 从先验知识狭义的角度定义,这些都是先验知识,但是进化计算并不强调依赖这些先验知识更快的解决搜索问题。原因是因为倘若不依赖这些先验知识,就需要设计非常优秀的搜索空间来提升进化计算的性能——这是通过完美的设计适应度函数来实现的。但是这样完美的设计反而更加依赖先验知识。因此在目前的科研领域中,进化计算算法的建模大部分的时候是会喂数据集作为训练集的,然后使用“预测与现实的差距”相关的统计定义来指定适应度函数。
为特定问题自动化地生成参数化拓扑结构表示的通解
遗传编程中解的表现是图形结构(graph structure), 对外表达为数学公式。一张图就是一个解的表达,图的大小、类型和连接性是由遗传编程决定的。用参数化的拓扑结构表示解的好处是每一个解的结构都是一致且通用的,并非是单纯的对一个问题解的事例(intance)。
如果遗传编程还包括条件发展运算符(if…,then…)吗,那么一般来说自由变量的不同实例将产生不同的图形结构,也就是说根据自由变量值的不同,最佳运行程序的执行将产生不同的图形结构。
那么,GP可以允许存在自动构建的循环程序吗?
享受了来自摩尔定律的红利
随着计算机科学的不断发展,计算机的性能越来越强大,遗传编程所需要的计算时间已经大幅度地降低。作者列出了作者的科研团队从1987年到2002年使用的电脑对遗传编程计算时间的缩短,结果表明1000个结点的奔腾II并行运算机器相比于最早使用的德州仪器的串行LISP机器对同一个遗传编程任务加速了13,900倍。其中为遗传编程程序带来最大提升的计算机技术莫过于并行计算。随着摩尔定律所带来的计算时间的大幅度缩短,现在的遗传编程可以生成更多的比拟人类的解决方案。
In other words, genetic progarmming is able to take advantage of the exponentially increasing computational power made available by iteration of Moore’s law——that is, it is Mooreware.